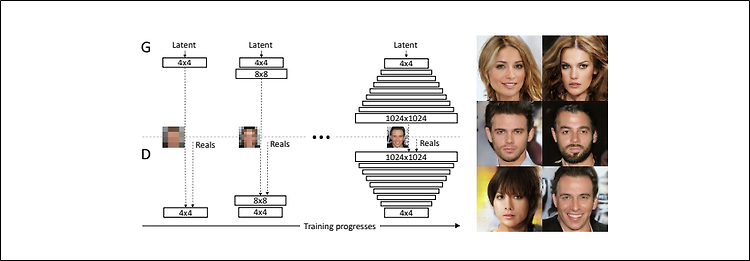
※ 일본 블로그 내용을 번역한 것으로 오역이나 직역이 있을 수 있으며, 내용의 오류 지적해주시면 감사하겠습니다. 1. 개요 현재 AI계에서 화제가 되고 있는 "Vision Transformer"에 대해 다뤄보려고 한다. 이번에 제안된 Vison Transformer(이하 ViT)이라는 모델에 의해 더 이상 레이어를 겹치는 형태의 모델은 없어질지도 모른다. ViT는 Transformer을 거의 그대로 이미지 분류 업무에 이용한 것으로, ImangeNet/ImageNet-ReaL/CIFAR-100/VTAB SoTA모델과 거의 비슷한 정도 혹은 그 이상을 성능을 달성하였다. 심지어 SoTA모델들(BiT/NoisyStudent)와 비교해서 계산 비용은 15분의 1까지 떨어졌다 (SoTA를 향상시킨 모델은 많아 ..