1. 교차 검증이 필요한 이유
데이터는 기본적으로 label이 있는 train, test set으로 구성되어 있다. 만약 train set을 다시 trainset + validaton set으로 분리하지 않는다고 가정하면, 우리는 모델 검증을 위해 test set을 사용하여야 할 것이다. 이 경우 한 가지 취약점이 존재한다. 고정된 test set을 이용해 모델의 성능을 확인하고 파라미터를 수정하는 과정을 반복하면 결국 내가 만든 모델은 test set에서만 잘 작동하는 모델이 되어버리고 만다. 즉, test set에 과적합(overfitting)되어 실제 데이터를 가지고 예측을 수행하면 제대로 된 결과를 얻을 수 없게 된다.
즉 고정된 train set과 test set으로 평가를 하고 반복적으로 모델을 튜닝하다보면 test set에서 과적합하는 문제가 야기되기 때문에 이러한 문제를 해결하고자 하기 위해 등장한 개념이 '교차 검증'이다.
그럼 교차 검증은 이 문제를 어떻게 해결할까? 이러한 과적합 문제는 test set 데이터가 일부분으로 고정되어 있기 때문에 발생하기 때문에 교차 검증을 통해 데이터의 모든 부분을 사용하여 모델을 검증하고 test set을 하나로 고정하지 않는다. 교차검증은 데이터의 분할을 몇번이고 반복 실행하여 복수의 모델을 훈련시킨 후 마지막은 복수의 모델의 평균치를 얻어 최종적인 성능을 얻는 것이 보통이다.
교차검증에는 여러 방법이 있는데, 일반적으로 가장 많이 쓰이는 방법은 K분할교차검증(k-fold cross-validation)이다.

K분할교차검증(k-fold cross-validation)에 대해 간단히 설명하자면, 전체 데이 셋을 k의 subset으로 나누고 k번의 평가를 실행한다. 단, test set을 중복 없이 바꾸어가면서 평가를 진행해야한다. 다음으로 그렇게 출력된 k개의 평가 지표 (예를 들면 정확도)를 평균으로 하여 최종적으로 모델 성능을 평가한다.

※ 참고로, K는 사람이 임의로 결정한다.
※ 참고로, 모델의 최종 성능은 복수 모델의 평가의 '평균'이 아닌 다른 계산법을 사용할 수도 있다.
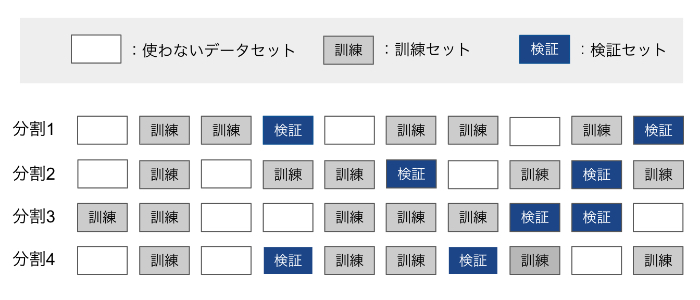
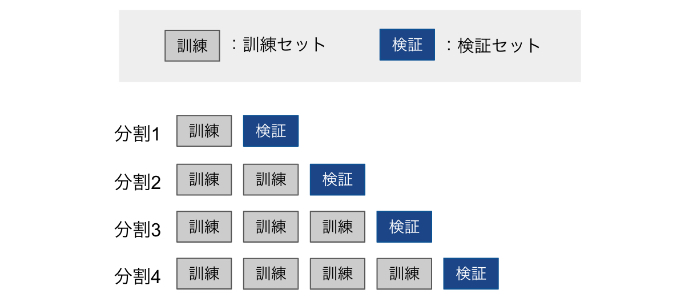
위의 설명을 조금 더 자세히 설명하자면, 10분할 교차 검증을 실시할 경우 아래의 흐름으로 교차검증이 진행된다.
| [교차 검증의 흐름] (10분할 교차검증의 경우) 먼저 전체 개발 데이터 세트를 10개의 subset으로 나누고 '9할은 훈련 세트', '1할은 테스트 세트로 한다' ↓ '훈련 데이터'로 모델의 학습을 실시한다. ↓ '테스트 세트'로 모델의 성능을 평가한다. ↓ 이 과정은 10회 반복하여 평가의 평균을 구해 성능을 평가한다. |
애매한 부분을 정리하자면, 10분할교차검증은 아래와 같은 이미지가 된다.
※ 이미지의 길이가 꽤 길기 때문에 주의

간단한 실습코드는 아래의 링크를 참고하길 바란다.
Data Science School
Data Science School is an open space!
datascienceschool.net
3.1. Cross-validation: evaluating estimator performance — scikit-learn 0.23.0 documentation
3.1. Cross-validation: evaluating estimator performance Learning the parameters of a prediction function and testing it on the same data is a methodological mistake: a model that would just repeat the labels of the samples that it has just seen would have
scikit-learn.org
2. 교차 검증의 장점과 단점
| 장점 | 단점 |
|
1. 모든 데이터 셋을 평가에 활용할 수 있다. - 평가에 사용되는 데이터 편중을 막을 수 있다. (특정 평가 데이터 셋에 overfit 되는 것을 방지할 수 있다.) - 평가 결과에 따라 좀 더 일반화된 모델을 만들 수 있다. 2. 모든 데이터 셋을 훈련에 활용할 수 있다. - 정확도를 향상시킬 수 있다. - 데이터 부족으로 인한 underfitting을 방지할 수 있다. |
Iteration 횟수가 많기 때문에 모델 훈련/평가 시간이 오래 걸린다. |
3. 교차 검증의 종류
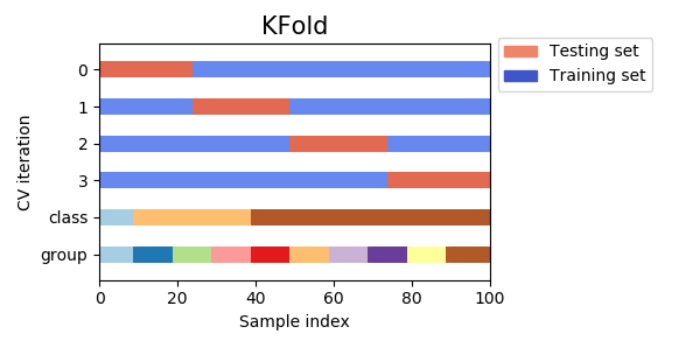
1) K분할 교차 검증 (K-fold cross-validation, k分割交差検証)
앞서 말했듯 가장 자주 사용되는 교차 검증 방법은 K분할 검증이다. 데이터를 K개로 분할하여, 그 중 하나를 테스트 데이터로써 사용하고, 남은 데이터는 트레이닝 데이터로써 사용한다. 이러한 방법을 통해 얻은 K번의 결과의 평균을을 구하여 평가 결과로하는 방법이다.
참고로 회귀 업무에서는 skikit-learn의 k분할교차검증을 기본으로 사용한다.
<사용예>
import numpy as np
from sklearn.model_selection import KFold
X = ["a", "b", "c", "d"]
kf = KFold(n_splits=2)
for train, test in kf.split(X):
print("%s %s" % (train, test))
# [2 3] [0 1]
# [0 1] [2 3]<처리 이미지>
2) 리브-원-아웃 교차 검증 (leave-one-out cross-validation, 一つ抜き交差検証)
리브-원-아웃 교차검증은 k분할 교차 검증에서 개별 분할 샘플이 하나밖에 없는 것이다. 즉, K개의 데이터를 K분할하여, K회 훈련과 테스트(하나의 샘플을 테스트 세트로하여)를 실행하는 경우를 리브-원-아웃 교차검증이라고 말한다.
이 방법은 데이터세트가 작은 경우 더 나은 추정이 가능하게 되는 방법이다. 덧붙여서 테스트 세트를 하나가 아닌 P개 사용하는 경우를, leave-p-out-cross-validation이라고 부른다.
<사용예>
from sklearn.model_selection import LeaveOneOut
X = [1, 2, 3, 4]
loo = LeaveOneOut()
for train, test in loo.split(X):
print("%s %s" % (train, test))
# [1 2 3] [0]
# [0 2 3] [1]
# [0 1 3] [2]
# [0 1 2] [3]<처리 이미지>

3) 리브-p-아웃 교차 검증(leave-p-out cross validation)
전체 데이터(서로 다른 데이터 샘플들) 중에서 p개의 샘플을 선택하여 그것을 모델 검증에 사용하는 방법이다. 따라서, test set을 구성할 수 있는 경우의 수(=훈련 및 검증에 소요되는 Iteration 횟수)는 아래와 같다.

k-겹 교차 검증 방법과 마찬가지로, 각 데이터 폴드 세트에 대해서 나온 검증 결과들을 평균내어 최종적인 검증 결과를 도출하는 것이 일반적이다. 이 교차 검증 방법은 구성할 수 있는 데이터 폴드 세트의 경우의 수가 매우 크기 때문에, 계산 시간에 대한 부담이 매우 큰 방법이다.

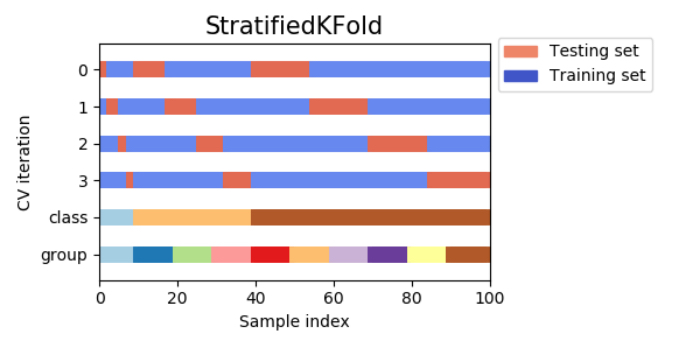
4) 계층별 k-겹 교차 검증(Stratified k-fold cross validation, 層化k分割交差検証)
단순한 K분할 교차 검증에서는 훈련 세트와 검증 세트를 포함한 클래스가 전부 다른 경우가 발생하여 정밀도가 0이되는 경우가 있다. 예를 들어 훈련 세트로 개의 이미지만 사용된 경우, 고양이의 이미지만을 사용해 결성된 검증 세트에 대해서 예측 정확도가 0이 되어버리고 만다.
이러한 현상이 일어나는 것을 방지하기 위해, 클래스 분류 업무에서는 계층별 k-겹 교차 검증을 사용하는 것이다. 각 분할에서의 클래스의 비율이 전체의 비율과 같도록 분할한다.
예를 들어, 샘플의 90%가 클래스 A, 10%가 클래스 B인 경우, 계층별 k-겹 교차 검증에서는 각각의 분할의 90%가 클래스A로 10%를 클래스B로 하도록 실행한다는 의미이다.
일반적으로 클래스분류기를 평가하기 위해 단순한 k분할 교차 분할 검증이 아닌 계층별 k-분할 교차검증을 사용하는 것이 신뢰할 수 있는 범화 성능을 추정할 수 있다. 예를 들어 샘플의 약 10%만 클래스 B로 한 경우에서 표준적인 K분할 교차검증을 실시하면 하나의 분할에 클래스 A만 들어 있지 않는 것이 보통이므로 이러한 단순 k-분할을 테스트 세트로써 사용해도 클래스 모델의 전체의 성능을 평가하는데 그다지 유용하지 않다.
<사용예>
from sklearn.model_selection import StratifiedKFold
X = np.ones(10)
y = [0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
skf = StratifiedKFold(n_splits=3)
for train, test in skf.split(X, y):
print("%s %s" % (train, test))
# [2 3 6 7 8 9] [0 1 4 5]
# [0 1 3 4 5 8 9] [2 6 7]
# [0 1 2 4 5 6 7] [3 8 9]<처리 이미지>

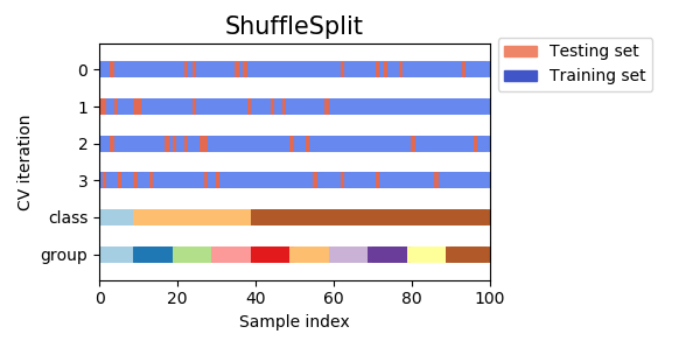
5) 셔플 스플릿 교차 검증(shuffle-split cross-validation,シャッフル分割交差検証)
셔플 스플릿 교차검증은 매회 train_size개의 샘플을 선택 추출하여 훈련 세트로써, 훈련 세트와 중복되지 않는 test_size개의 샘플을 선택해 테스트 세트로한다. 이것을 n-iter회 반복하는 방법이다.
예를 들어, 아래의 그림에서 10개의 샘플에서 데이터 세트를 훈련 세트 사이즈 5, 테스트 세트 사이즈 2로 4회 분할할 수 있다.
셔플 스플릿 교차 검증에서는 훈련 세트와 데이터 세트의 사이지에 관계없이 반복하는 횟수를 설정할 수 있으며, 더욱이 train_size와 test_size의 합이 1이 되지 않도록 하는 것으로 데이터를 전체 사용하지 않고 일부만을 사용하는 것으로 설정할 수도 있다.
셔플 스플릿 분할교차검증은 데이터 세트가 매우 큰 경우에 유용하게 활용된다. 덧붙여서 셔플 스플릿 분할교차검증을 계층별로한 것을 계층별 셔플 분할 교차 검증이라고 부르며, 클래스 분류 업무에서 보다 신뢰할 수 있는 결과를 얻을 수 있다.
<사용예>
from sklearn.model_selection import ShuffleSplit
X = np.arange(10)
ss = ShuffleSplit(n_splits=5, test_size=0.25, random_state=0)
for train_index, test_index in ss.split(X):
print("%s %s" % (train_index, test_index))
# [9 1 6 7 3 0 5] [2 8 4]
# [2 9 8 0 6 7 4] [3 5 1]
# [4 5 1 0 6 9 7] [2 3 8]
# [2 7 5 8 0 3 4] [6 1 9]
# [4 1 0 6 8 9 3] [5 2 7]<처리 이미지>
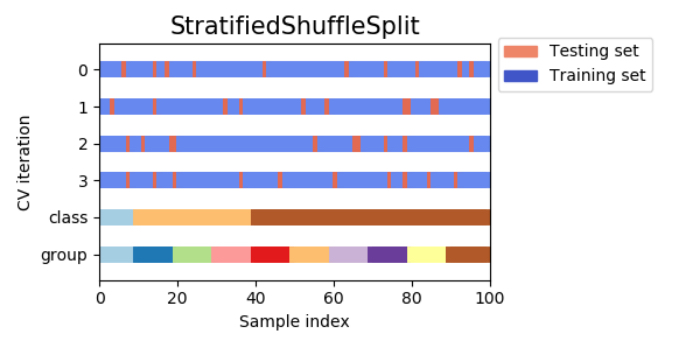
6) 계층별 셔플 스플릿 교차검증(stratified-shuffle-split cross-validation,層化シャッフル分割交差検証)
앞의 셔플 스플릿 교차검증의 특징으로 훈련 세트와 데이터 세트의 사이즈에 관계없이 반복 횟수를 설정할 수 있고 데이터의 일부만을 이용하도록 설정할 수 있다고 하였다. 계층별 셔플 스플릿 교차검증은 셔플 스플릿 교차 검증의 한 종류로, 각 분할내에서 클래스의 비율이 전체의 비율과 같도록 분할한다.
<처리 이미지>
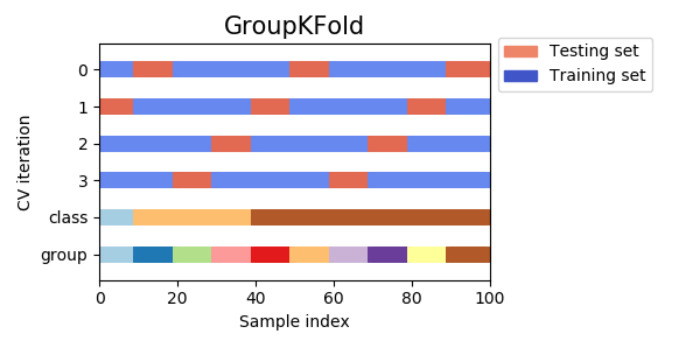
7) 그룹 k 분할 교차검증 (group k-fold cross-validation, グループk分割交差検証)
그룹 k 분할 교차검증은 훈련 세트와 데이터 세트를 같은 그룹에 포함되지 않도록 k분할 교차 검증하는 것이다. 설명하자면, 예를 들어 얼굴 이미지로부터 감정을 인식하는 시스템을 만들기 위해 100명의 사람이 각각 다양한 감정을 표현하는 얼굴 이미지를 모았다고 가정해보자.
클래스 분류 모델의 목표는 데이터 세트에 존재하지 않는 사람의 감정을 정확히 예측하는 것이다. 이 데이터 세트에 대해서도 계층별 분할 교차검증을 적용하면, 훈련 세트와 테스트 세트의 양쪽 모두에 같은 인물의 얼굴 사진(감정이 다른)이 포함된 것이다. 이 경우 학습된 모델이 훈련 세트에 포함된 인물의 감정을 예측하는 것은 전혀 본 적없는 사람의 감정을 예측하는 것보다는 간단한 것은 틀림없다.
여기서 전혀 본적 없는 사람의 감정을 예측하는 정확도를 확실히 평가하기 위해서는 훈련 세트와 테스트 세트에 포함된 인물이 겹치지 않도록 할 필요가 있다. 이러한 상황에서 도움이 되는 것이 바로 그룹 k분할 교차검증이다.
그룹 k분할 교차검증이 도움이 되는 다른 방면을 예를 들자면, 환자로부터 얻은 복수의 샘플을 바탕으로 새로운 환자에 대해서 예측을 실행하는 의료용 어플이나 사람의 말로부터 얻어진 복수의 녹음데이터를 바탕으로 또 다른 화자의 말을 인식하는 음성 인식 어플에도 적당하다.
<사용예>
from sklearn.model_selection import GroupKFold
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
gkf = GroupKFold(n_splits=3)
for train, test in gkf.split(X, y, groups=groups):
print("%s %s" % (train, test))
# [0 1 2 3 4 5] [6 7 8 9]
# [0 1 2 6 7 8 9] [3 4 5]
# [3 4 5 6 7 8 9] [0 1 2]<처리 이미지>
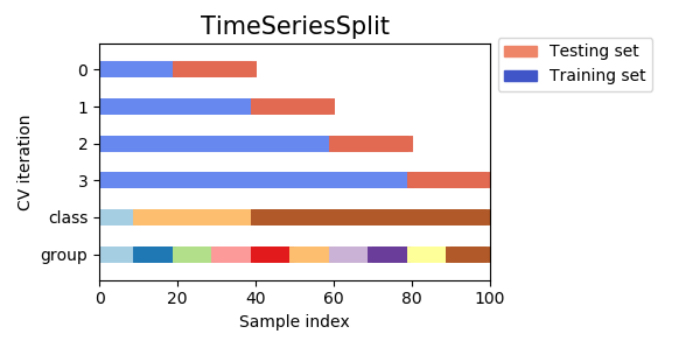
8) 시계열 분할 교차검증 (time series split cross-validation, 時系列分割交差検証)
시계열 분할 교차검증은 그 이름 대로 시계열 데이터를 사용한 분할법이다. 참고로 아무 생각없이 시계열 데이터를 k분할 교차검증하면 큰일나므로 절대로 주의할 필요가 있다.
단순히 k분할검증을 하면, 데이터의 순서에 큰 의미가 있는 시계열 데이터를 뒤죽박죽 섞어 버리게 된다. 즉 미래와 과의 데이터를 혼동한 훈련 세트로 학습을 실시해버리게 되어, 모델이 각 시점에 어떤 일이 일어났는지를 제대로 학습할 수 없게 되어버린다. 예를 들어 환율을 예측하는 모델의 경우, 훈련 세트에 미래의 가격 변동 등의 정보가 들어가버려 예측 정밀도가 이상하게 높아져 범화 성능이 낮아지는 이상한 상황이 발생한다.
이러한 현상은 시계열 분할을 사용하면 예방이 가능하다. 시계열 분할의 방법을 적용한다면 다음과 같은 이미지가 된다. 훈련 세트를 시계열의 오래된 데이터부터 하나씩 더해간다.
위의 그림을 일반화하면, 데이터가 전체 n 샘플이 되는 경우, 교차검증용의 데이터를 k샘플확보하려고 할 때,
[1회째의 분할]
훈련 데이터 : n-k샘플
검증 데이터: n-k+1번째의 1샘플만
↓
[2회째의 분할]
훈련 데이터: n-k+1샘플
검증 데이터: n-k+2번째의 1샘플만
↓
.
.
.
이와 같이 1샘플씩 훈련 데이터를 증가시켜가며 학습은 교차 검증을 k회반복하여, 그 k회분의 교차검증으로부터 얻어진 예측값과 실측값과의 RMSE(회귀의 평가지표)를 산출하는 방법이다.
그러나 이방법은 검증 기간에 따라 훈련 세트의 량이 다르기 때문에, 예를 들어 1회째와 4회째의 검증때의 모델 정밀도가 크게 다르게 되는 경우가 보통 일어나, 검증에 따라 운용시의 모델 정밀도를 정확히 파악하는 것이 어렵다. 이런 교차검증의 방법은 데이터가 적은 경우에 잘 사용되며, 모델 운용시의 정확도를 파악하기 위해 데이터 량과 정확도 향상의 관계도 함께 파악할 필요가 있다.
<사용예>
from sklearn.model_selection import TimeSeriesSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([1, 2, 3, 4, 5, 6])
tscv = TimeSeriesSplit(n_splits=3)
print(tscv)
TimeSeriesSplit(max_train_size=None, n_splits=3)
for train, test in tscv.split(X):
print("%s %s" % (train, test))
# [0 1 2] [3]
# [0 1 2 3] [4]
# [0 1 2 3 4] [5]<처리 이미지>
9) 슬라이드형의 교차검증 (スライド型の交差検証)
또 다른 시계열 데이터 분석의 교차 검증의 방법은, 훈련과 검증에 이용하는 데이터를 슬라이드하는 방법으로 교차검증을 실시하는 것으로 효과적인 방법 중 하나이다. 훈련 세이트의 사이즈를 window로 지정하여, 이것을 슬라이드하여 항상 일정 크기의 훈련 세트를 사용하는 방법이다.
예를 들어 데이터 세트를 3개로 분할하여, 훈련 세트로 6개월 분, 검증 세트로 2개월 분, 슬라이드의 기간을 2개월분으로 한 경우를 표현하면 다음과 같은 이미지가 된다.
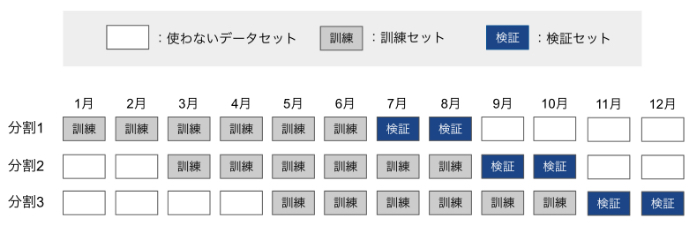
이와 같이 기간을 슬라이드하는 형태로 훈련 세트와 검증 세트를 만들어가는 것이다.
참고자료
https://aizine.ai/glossary-crossvalidation/
https://aizine.ai/cross-validation0910/
https://qiita.com/LicaOka/items/c6725aa8961df9332cc7
https://datascienceschool.net/view-notebook/266d699d748847b3a3aa7b9805b846ae/
'IT > AI\ML' 카테고리의 다른 글
| [python] 머신러닝의 모델 정밀도 향상에 효과적인 학습곡선과 검증곡선 입문 (0) | 2020.05.25 |
|---|---|
| 머신러닝 정밀도의 향상을 위해 해야할 것 (0) | 2020.05.24 |
| GAN ; WGAN & WGAN-gp (0) | 2020.05.01 |
| GAN ; 잠재 변수와 생성 이미지 (0) | 2020.05.01 |
| [논문] GAN ; CycleGAN (Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks) (2) | 2020.04.30 |