이번에 설명할 논문은 Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks이다. 본 논문의 테마는 '순환에 의한 일관성을 가지는 적대성 네트워크' 를 이용한 '비지도 학습'으로 '이미지부터 이미지에의 전환'이다.
1. 개요
제안 방법의 최종적인 목표는 쌍이 되는 훈련 데이터없이 (즉 비지도 학습으로), 소스 도메인 X로부터 대상 도메인 Y로의 이미지 변환을 실시하는 것이다.

즉, 훈련 데이로터로써 각각이 짝이 되지 않은 두 개의 이미지 군집을 전달해, 말 → 얼룩말, 경관사진→모네의 그림이라는 사진의 이미지를 학습해, 한 쪽으로부터 다른 한쪽에 자동적으로 변환이 되도록 하는 것이다.
구체적으로는 타겟의 분포 Y와 구별 할 수 없을 것 같은 분포 G(X)를 생성하는 대응관계(사상) G를 '적대성 손실'을 이용해 학습시키는 것이다. 그러나 '적대성 손실'을 이용하는 것으로는 구속력이 부족하므로, 역대응관계(사상)F와 '사이클링 손실함수'를 도입하여, F(G(X))가 X로를 복원할 수 있도록 교정한다. (역방향의 변환에 관해서도, 동일한 접근으로 한다)
위의 그림과 같이. 사진의 텍스트를 바꾸거나, 물체를 변환 시키거나, 계절을 전환시키거나, 나중에 소개하겠지만 이미지의 Enhancement등, 많은 사례에서 성과를 거두고 있다.
2. 도입
본 논문은 학습을 위한 방법으로 주로 다음과 같은 방법을 사용하고 있다고 설명한다.
① 어떤 이미지 군집의 특징을 추출한다.
② 그러한 특징이 다른 이미지군을 어떻게 변화시킬 수 있는가에 대해 이해한다.
※ 그러나 다음과 같이 짝이 되는 훈련 데이터없이 학습을 진행한다.

위 그림과 같이, 이미지 Xi와 대응하는 이미지 Yi가 전달된다 = 짝 (지도 학습), 단순한 (특히 대응하지 않는)이미지 군집 X와 이미지 군집 Y가 전달된다 = 짝이 되지 않음 (비지도 학습) 으로 취급한다.
물론, 짝의 훈련 데이터가 있으면 제일 좋지만, 그렇게 준비하는 것은 실제로 힘들며, 예를 들면, 아까와 같은 풍경 사진과 어떤 화가의 그림 스타일으로 변환시키는 등의 업무에서는 '이미 이 세상에 존재하지 않는 화가'를 대상으로 하는 경우, 그 풍경 사진에 일치하는 그림을 훈련 데이터로써 사용하는 것이 불가능하다. 따라서 이러한 업무에 짝을 이루는 훈련 데이터(지도 학습)을 이용하기에는 어렵고 실용적이지 않다.
그러므로, 현실적으로 손에 넣을 수 있는 훈련 데이터로써, 단순한 풍경 사진의 이미군집과 그림 작품의 이미지 군집을 전달하여, 이 두 개의 이미지간의 근저에 있는 관계성을 학습하자는 것이 제안 방법의 최대 목표가 된다. 구체적인 구현에 관해서는 PyTorch와 Torch로 구현된 Github를 참고하길 바란다.
또한, 본 논문중에서 소개하지 않는 생성 결과나 손실 예 등은 학자 홈페이지에 있으므로 홈페이지에서 확인해보길 바란다.
3. Cycle-Consistent Adversarial Networks
지금부터 제안 방법의 구체적인 내용에 들어간다. 최종적인 목표로써는 훈련 데이터로써 전달된 두 개의 도메인 X와 Y의 대응관계를 학습하는 것이므로 이것을 달성하기 위한 목적 함수로는 다음의 두 가지 함수를 도입하고 있다.
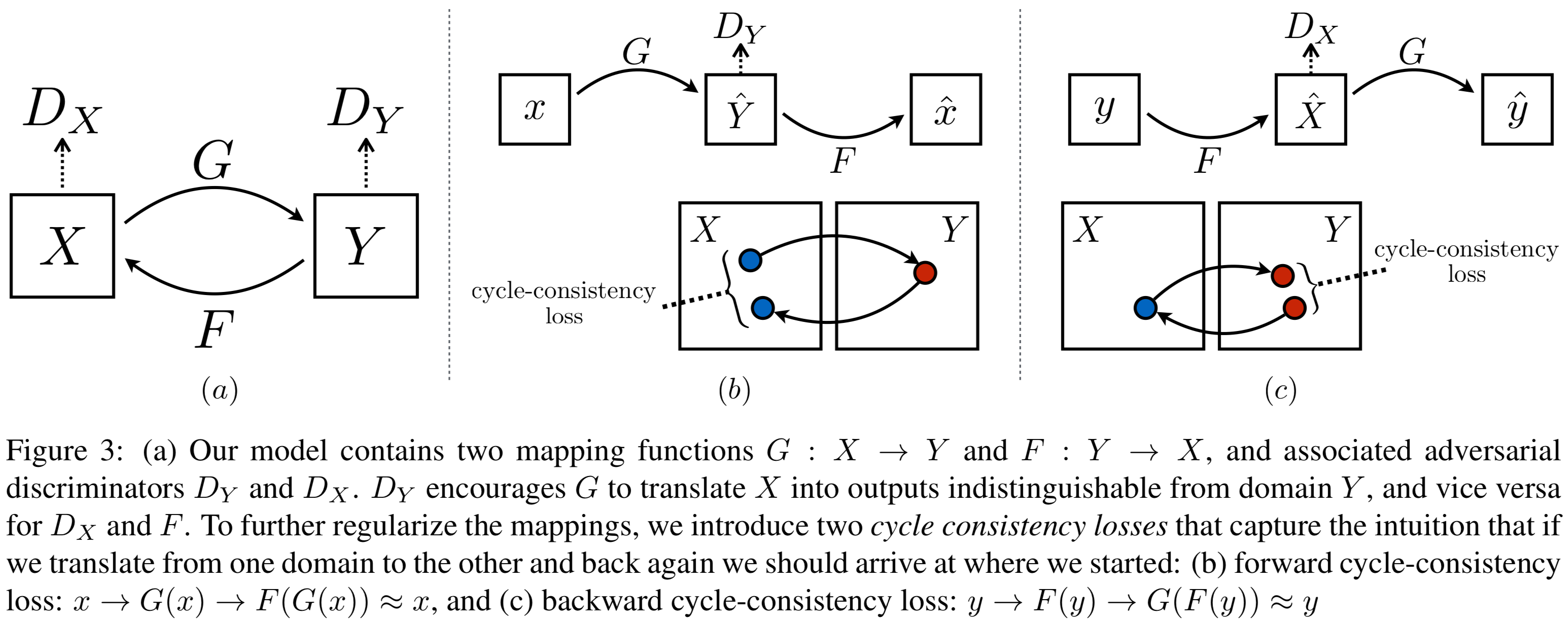
위 그림과 같이, 이런 모델은 'X로부터 Y로의 사상 G'와 'Y로부터 X에의 사상 F'의 두 가지의 생성기를 가진다. 그리고 '도메인 Y의 이미지y'와 '도에인 X의 이미지x를 변환시킨 G(x) = Y''의 진위를 판단하기 위한 판별기 Dy, 동일하게 한편으로 생성기 F에 대응하는 판별기 Dx를 준비한다.
논리적으로는 최적의 생성기 G는 '도메인 X'로 부터 '도메인 Y에 한없이 가까운 분산 Y''로 변환을 해야하지만, 그것과 같은 분산을 유도하는 사상은 무한으로 간주되거나, 모든 입력이 비슷한 출력에 맵핑되어 학습이 제대로 이루어지지 않는 발생할 수 있다.
그러므로, '순한에 의한 일관성'이라는 것을 가지는 것으로, F(G(x))≈x,G(F(y))≈y로 일치 여부를 확인하고 G와 F가 서로 '역사상' 그리고 '전단사(1대1일대응)' 이라는 것을 검증하는 것이 가능하다.
4. 적대성 손실
소스 도메인 X로 부터 타겟 도메인 Y에의 변환의 학습에 이용되는 '손실성함수'는 다음과 같은 나타낼 수 있다.

G : 타겟 도메인 Y에 가까운 이미지 G(x)를 생성하는 Generator
Dy: 생성된 이미지 G(x)와 실제의 샘플 y를 식별하는 Discriminator
그러나, 이것으로는 직감적으로 이해하기 힘드므로, G(x)=y'로써 위의 식을 구분하기 쉽게 나눠쓰면 아래와 같다.

p는 대상이 진짜인 경우의 '진정한 확률 분포'를 나타내고, 제 1항목부터 순서대로,
- pdata(y)logDY(y) ... y를 '실제'로 정확히 판별할 수 있는 경우
- (1−pdata(y))log(1−DY(y)) ... y를 '가짜'라고 정확히 판별할 수 있는 경우
- py′(y′)logDY(y′) ... y'를 '진짜'라고 정확히 판별할 수 있는 경우
- (1−py′(y′))log(1−DY(y′)) ... y'를 '가짜'라고 정확히 판별할 수 있는 경우
각각의 교차 엔트로피 오차를 나타낸다.
그러나 전제로써 소스인 y가 전부 '진짜'이며, 생성된 y'가 전부 '가짜'이므로,

위 식과 같이, 제 1항목과 제 4항목 만이 남아, 처음의 식이 도출된다.
Discriminator은 식별가능한 정확도를 높여, 목적 함수를 크게하는 방향으로 끌고가지만, Generator은 생성한 이미지를 진짜라고 생각되도록 Discriminator을 속이기 위해 반대로 목적 함수를 작게하는 방향으로 끌고 간다.
그로 인해 최종적으로 구해지는 식은 아래와 같다.

역방향의 변환 학습에 관해서도 다음과 같은 동일한 목적함수를 도출해낸다.

본래, Generator의 학습에는 '소스'와 '생성한 이미지'의 분포간 거리를 좁히기 위해서 JS발산의 최소화를 하지만, 이것은 성립하는 것은

위의 조건 일때, 즉 전달된 훈련 데이터의 '진짜'와 '가짜'의 비율을 1대1로 해야만 한다. 따라서 N=N'=M보다, 아래의 식이 된다.

Discriminator자체의 학습에서는, 아까와 같이 교차 엔트로피 오차를 최소화하지만, 이러한 목적함수는 부호를 역전하기도하므로, 아까의 미니 맥스원리로 떨어 뜨리고 있다는 점에 관해서도 정확한 것인지 확인할 수 있다. 또한, Generator의 학습은 소스의 식별에 의존하지 않으므로, 최초의 항목을 생략해 아래처럼 나태낼 수 있다.

5. 사이클 일관성 손실
사이클 일관성 손실에 관해서는 아래처럼 L1법칙을 이용하여 기대 값의 형으로 나타낼 수 있다.

식으로 부터 알 수 있듯, '변화 후의 이미지로부터 입력 데이터를 복원한 이미지'와 '원래 입력 데이터'를 비교하는 것으로 손실을 산출한다.

위 그림은 오른쪽으로 부터 순서대로, 입력 데이터, 변환후의 이미지, 복원한 이미지이다. 일관성 손실을 이용하여 복원된 이미지는 입력 이미지에 상당히 가까운 것이 되었으며, 제일 아래의 예의 항공사진은 지도에 비교해서 많은 정보를 가지고 있음에도 불구하고, 지도로부터 항공사진의 복원조차도 가능하다.
6. 적대성 손실 + 사이클 일관성 손실
'적대성손실'과 '사이클 일관성 손실'을 종합하는 것으로, 최종적인 목적 함수를 설정한다.

그러나, 이것은 상대적인 가중치를 제약하는 계수 λ를 도입하고 있다. 마지막으로 아래의 식을 구하는 것으로 모델의 학습을 한다.

7. 검증 결과
아래의 다섯개의 선행연구와 비교한다.
- CoGAN
- SimGAN
- Feature loss+GAN
- BiGAN / ALI
- pix2pix
pix2pix에 대해서는 짝이 되는 훈련 데이터를 사용하는 학습모델이기 때문에, 짝이 되지않은 훈련 데이터를 이용하여 학습을 하 방법이 얼마나 거기에 가까워질 수 있는지를 검증한다.
또한, '적대성손실'과 '사이클일관성손실' 각각의 중요성을 확인하기 위해서는 그것들을 조합을 바꾼 여러 모델과 비교한다.

위 그림에서 알 수 있다. 다른 어떤 방법은 제대로된 결과가 나오지 않고 있는 중, 제안 방법은 지도학습인 'pix2pix'와 동등의 퀄리티의 변환을 실현하고 있다.

'Cycle alone'과 'GAN+backward'에는, 원래 대상으로 이미지를 생성할 수 없고, 'GAN alone'과 'GAN+forward'에서는 입력 이미지를 무시하고 모드 붕괴(Discriminator을 속이기 쉬운 이미지만을 생성해버리고마는 현상)이 일어난다.
특히 제거된 상성의 방향에 대해서, 모드 붕괴가 일어나는 것을 확인할 수 있다.
8. 응용예
1) Collection Style Transfer


선행 연구인 'Neural Style Transfer'과 달리, 어떤 하나의 그림의 작풍에의 변환이 아닌, 작품군전체의 작풍의 모방하는 것이 가능하다. 즉, 고흐의 '별이 빛나는 밤에'가 아닌 그의 작풍이 가진 특징을 학습할 수 있는 것이다.
2) Object Transfiguration / Season Transfer

3) Photo Generation from Paintings


이 업무에서는 입력과 출력의 간에 색의 구성을 유지하기 위해, 다음과 같은 손실함수를 추가로 도입하였다.

L1법칙을 이용해, '입력'과 '생성한 이미지'의 분산이 가까워지도록 손실함수를 설정한다.
4) Photo Enhancement

소스에는 스마트 폰등 촬영 이미지 소자의 작은 카메라에 의해 촬영된 피사계 심도의 깊은 사진, 타겟에는 (촬영된 이미지 소자가 크고, 피사계 심도가 얕은) DSLR 카메라로 촬영된 사진을 이용하는 것으로, 피사계심도가 더 얕은 사진으로 변경이 가능하다.
9. Neural Style Transfer과의 비교

'Neural Style Transfer' 의 지도 데이터로써, 두 개의 대표적인 작품을 전달한 것과 비교하고, 평균그램행렬을 이용하여 얻은 타켓의 평균적인 작풍부터, 작품군전체에 대하여도 동일한 비교를 실행한다.

Neural Style Transfer에서는 원했던 출력에 가까운 이미지를 입력으로 전달할 필요가 있다는 것을 알 수 있다.
10. 이후의 결과

위 그림은 몇 가지 실패 예시이다. 지금까지의 업무와 같이, 색이나 텍스쳐에 관한 변환은 성공하고 있지만, 형상을 변형하는 업무에서는 제대로 작동되지 않는다.
예를 들어, 개에서 고양이로 변환하는 업무에서는, 입력은 거의 변화하지 않고 있다. 이것은 외관적인 모양이 잘 보일수 있도록 Generator가 조정을 하는 것으로 부터 기인한 것으로 생각된다. 또한, 전달된 훈련 데이터의 특징에 의해 기인한 실패 사례도 있다. 제일 오른쪽에 있는 것처럼, 말에서 얼룩말의 변환에 있어서 원했던 결과가 나오지 않고 있다. 이때, 훈련시에는 야생의 말과 얼굴말의 데이터만 전달하지 않고, '승마'라는 사람을 포함한 상황은 가정하지 않았다. 그래서, 짝이 되는 훈련 데이터를 전달한 경우와 짝이 없는 훈련 데이터를 전달한 경우에서는, 여전히 차이가 나버리는 문제도 남아있다. 사진에서 레이블로 변환하는 작업에서는, 나무와 건축물을 혼동해버리는 경우도 있다. 이런 애매한을 해결하기 위해서는 무엇인가 약한 제약이 필요하다고 생각된다.
참고자료
https://qiita.com/hikaru-light/items/98d06b21b4f3e2bb6ca4
'IT > AI\ML' 카테고리의 다른 글
| GAN ; WGAN & WGAN-gp (0) | 2020.05.01 |
|---|---|
| GAN ; 잠재 변수와 생성 이미지 (0) | 2020.05.01 |
| [python] GAN; cGAN(conditional GAN) (2) | 2020.04.30 |
| [python] PCA와 ICA의 개요와 차이점 (2) | 2020.04.30 |
| Manifold Learning(多様体学習)과 알고리즘 (0) | 2020.04.30 |