1. Case Study - News Categorization
지금까지 배운 List Comprehension, Data Structure(Collections), Pythonic Code 작성법 등을 기반으로 다른 패키지 사용 없이 Python만으로 어떠한 뉴스와 비슷한 뉴스를 찾아내도록 코드를 작성해보자.
1) 문자를 컴퓨터에게 알려주기
(1) 이진수만 이해하는 컴퓨터는 문자 자체를 인식할 수 없으므로 문자를 숫자로 변형시켜줘야한다.
(2) 숫자로 '비슷함'을 표현한다는 것은 '가까움'을 표현하는 것이다.
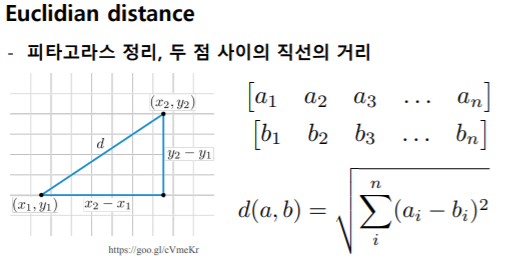
수학적으로 좌표 평면상에 위치한 가장 가까운 두 점은 유사하다고 할 수 있다. 그래프 상에 위치한 두 점 사이의 거리는 피타고라스 정의로 구할 수 있다. 정리하면 숫자를 (좌표 평면상에 표현할 수 있도록)벡터 값으로 바꾸어 두 점 사이의 거리를 구함으로써 유사한지를 알 수 있다. 즉, 문자 > 숫자 > Vector로 변형할 필요가 있다.
(3) 문자를 Vector로 바꾸는 방법 - One-hot Encoding
문자를 Vector로 바꾸는 여러 방법이 있지만 여기서는 One-hot Encoding라는 방법을 이용할 것이다.

하나의 단어를 Vector의 Index로 인식하기 위해서는 Vector Space라는 것을 만든다. Vector Space란 각각의 글자들이 어떤 인덱스에 포함되는지를 정의해놓은 공간이라고 할 수 있다.
어떤 문장(혹은 문서)에 n개의 단어가 있다면 n개의 인덱스를 가지는 리스트를 만들고 그 문장(혹은 문단)에 각 인덱스에 해당하는 문자가 몇 개가 있는지 카운트한다. 즉, 단어별로 인덱스를 부여해서, 한 문장(또는 문서)의 단어의 개수는 Vector로 표현하는 것이다. 이러한 기법은 Bag of words라고 한다.

그리고 이렇게 표현된 것은 코퍼스(corpus; 자연언어 연구를 위해 특정한 목적을 가지고 언어의 표본을 추출한 집합)셋이라고 할 수 있다. 그 단어들의 인덱스를 가지고 있는 dict가 있다고 생각하면 된다.
(4) 그 다음 유사성은 어떻게 표현하는가?
위에서 얘기했듯 피타고라스 정의를 이용해 두 점 사이의 직선 거리를 구하는 방법(Euclidian distance)이 있다. 그 외에도 두 점 사이의 각도 (Cosine distance)를 측정해서도 결과를 얻을 수 있다.

실제로 문장(혹은 문서)의 유사성을 구하는 방법에는 두 점 사이의 각도를 구하는 Cosine distance를 주로 사용한다. 데이터셋이 작으면 Euclidian distance를 이용해도 괜찮으나, 데이터셋이 크면 클 수록 Cosine distance의 쪽이 더 좋은 결과 값을 출력한다.
2) Process
- 파일 불러오기
- 파일을 읽어서 단어사전 (corpus) 만들기 ( ; split > 소문자 > set으로 묶어주기 )
- 단어별로 Index 만들기 ( ; dict로 인덱스 생성 )
- 만들어진 인덱스로 문서별로 Bag of words vector 생성
- 비교하고자 하는 문서 비교하기 ( ; Cosine distance 사용해 문서들 간의 유사성 비교 )
- 얼마나 맞는지 측정하기
import os
# 디렉토리의 이름을 입력하면 그 안에 file을 가져오는 함수
def get_file_list(dir_name):
return os.listdir(dir_name)
def get_conetents(file_list):
y_class = []
X_text = []
# 0 일때 야구, 1일 때 축구이다. file명 맨 앞의 숫자가 1~4이면 0인 야구로 분류하고, 그 외에는 1인 축구로 분류
class_dict = {
1: "0", 2: "0", 3:"0", 4:"0", 5:"1", 6:"1", 7:"1", 8:"1"}
for file_name in file_list:
try:
# encoding 'cp949'는 Windows, 'UTF-8' mac이나 Linux OS이다.
# 여기서는 Windows에서 수집했기 때문에 cp949로 해야 제대로 읽힌다.
f = open(file_name, "r", encoding="cp949")
# os.sep이란 OS에 따른 파일 구분 기호
# 여기에서는 야구에 관한 기사인지, 축구에 관한 기사인지만 나눔
category = int(file_name.split(os.sep)[1].split("_")[0])
y_class.append(class_dict[category])
X_text.append(f.read())
f.close()
except UnicodeDecodeError as e:
print(e)
print(file_name)
return X_text, y_class
# 하나의 단어에 대해 의미없는 문장 부호 등을 제거하고 소문자로 변환하는 함수
def get_cleaned_text(text):
import re
text = re.sub('\W+','', text.lower() )
return text
# 텍스트들의 워드 각각에 인덱스를 만들어 주는 작업
def get_corpus_dict(text):
# text(사실상 80개의 문서)의 문장(sentence)을 단어 단위로 나눠서 다시 text에 할당(two dimensional array형태)
text = [sentence.split() for sentence in text]
# 뽑아낸 단어들을 다시 one dimensional array형태로 바꿔준다.
cleaned_words = [get_cleaned_text(word) for words in text for word in words]
from collections import OrderedDict
corpus_dict = OrderedDict()
# cleaned_words에 대해 set을 해주는 이유는
# corpus를 만들기 위해 중복되는 단어를 제거한 후,
# enumerate를 이용해 인덱스를 부여해야하기 때문이다.
# 중복되는 단어가 존재하지 않으므로 단어 자체가 키 값이 된다.
for i, v in enumerate(set(cleaned_words)):
corpus_dict[v] = i
return corpus_dict
# 문서별로 Bag of Words Vector 생성
def get_count_vector(text, corpus):
text = [sentence.split() for sentence in text]
# get_cleaned_text를 통해 앞서 전처리 방식과 동일하게 전처리를 한다.
# 같은 방식의 전처리를 사용하는 이유는 corpus의 key 값을 사용해서 그 값의 인덱스 값을 가져오는 방식이기 때문에,
# 그 key값과 동일해야기 때문이다.
# 최종적으로, [corpus[get_cleaned_text(word)]는 인덱스 숫자 형태로 바뀌게 된다.
word_number_list = [[corpus[get_cleaned_text(word)] for word in words] for words in text]
# python의 for문에서 변수 앞에 언더바(_)가 있는 경우가 있는데,
# 그 변수를 사용하지 않겠다는 의미이다. 즉 여기서는 모든 값을 0으로 채워주기 위해 변수를 사용하지 않았다.
# 80 x 4032의 0으로 채워진 matrix가 생성되었다.
X_vector = [[0 for _ in range(len(corpus))] for x in range(len(text))]
for i, text in enumerate(word_number_list):
for word_number in text:
X_vector[i][word_number] += 1
return X_vector
# 문서끼리 비교하는 함수
import math
# 여기서 v1, v2는 하나의 문서에 대한 4032개의 Vector를 의미
def get_cosine_similarity(v1,v2):
"compute cosine similarity of v1 to v2: (v1 dot v2)/{||v1||*||v2||)"
sumxx, sumxy, sumyy = 0, 0, 0
for i in range(len(v1)):
x = v1[i]; y = v2[i]
sumxx += x*x
sumyy += y*y
sumxy += x*y
return sumxy/math.sqrt(sumxx*sumyy)
def get_similarity_score(X_vector, source):
source_vector = X_vector[source]
similarity_list = []
for target_vector in X_vector:
similarity_list.append(
get_cosine_similarity(source_vector, target_vector))
return similarity_list
# 비교 결과 정리하기
def get_top_n_similarity_news(similarity_score, n):
import operator
x = {i:v for i, v in enumerate(similarity_score)}
# sorted를 이용해서 key값으로 정렬
sorted_x = sorted(x.items(), key=operator.itemgetter(1))
return list(reversed(sorted_x))[1:n+1]
def get_accuracy(similarity_list, y_class, source_news):
source_class = y_class[source_news]
return sum([source_class == y_class[i[0]] for i in similarity_list]) / len(similarity_list)
if __name__ == "__main__":
dir_name = "news_data"
file_list = get_file_list(dir_name)
# python에서는 상대경로를 찾아가야 하기 때문에, 파일이 있는 폴더명이랑 파일명을 os.path.join해줘야한다.
# '+'를 사용하지 않고 os.path.join을 하는 이유는 각 OS마다 폴더 구분 기호가 다르기 때문이다.
file_list = [os.path.join(dir_name, file_name) for file_name in file_list]
# X_test는 80개의 문서에서 추출된 문자들이 two dimensional array형태로 존재
# y_class는 80개의 문서을 0과 1로 카테고리를 나눈 데이터가 들어있다.
X_text, y_class = get_conetents(file_list)
corpus = get_corpus_dict(X_text)
print("Number of words : {0}".format(len(corpus)))
X_vector = get_count_vector(X_text, corpus)
source_number = 10
result = []
for i in range(80):
source_number = i
similarity_score = get_similarity_score(X_vector, source_number)
similarity_news = get_top_n_similarity_news(similarity_score, 10)
accuracy_score = get_accuracy(similarity_news, y_class, source_number)
result.append(accuracy_score)
print(sum(result) / 80)2. Machine Learning Overview & An understanding data
이번에는 Machine Learning에서 사용하는 용어(Model, Feature, Data Type) 등 개념에 대해 알아본다.
1) Model
예측을 위한 수학 공식, 함수 1차 방정식, 확률분포, condition rule
2) Algorithms
어떠한 문제를 풀기 위한 과정, Model을 생성하기 위한 (훈련) 과정
3) Model을 학습할 때, 영향을 주는 것들
예를 들면 아래와 같이 표현할 수 있다.

그러나 y 값에 영향을 주는 것은 x값 하나뿐이 아니다. 즉 아래와 같이 여러 개 존재할 수 있으며 이렇게 y값에 영향을 주는 x들을 특징(feature)라고 부른다.

4) Feature
- 머신러닝에서 데이터의 특징을 나타내는 변수이다.
- feature, (통계학에서는)독립변수, input 변수 등은 동일한 의미로 사용된다.
- 일반적으로 Table 상에 Data를 표현할 때, Column을 의미한다.
- 하나의 data instance(실제 데이터)는 feature vector로 표현한다.
[cf] 논문에서 Scalar는 이탤릭체, vector는 소문자 볼드, matrix는 대문자 볼드로 기재한다.
- Fature 별로 Data의 유형이 다르다.
| 연속형 값(continuous) | 이산형 값(discrete) |
| 값이 끊어지지 않고 연결됨 (예) 온도, 시험평균 점수, 속도 등 일반적으로 실수 값들 |
값이 연속적이지 않음 (예) 성별, 우편주소, 등수 등 Label로 구분되는 값들 |
| Numeric Types | Nominal Types | Ordinal Types |
| - 정력적으로 측정 가능한 Data type - 일반적으로 정수(integer) 또는 실수(real-number)로 표현 - 온도, 자동차 속도, 날짜의 차이(year or day) - 단위(scale)이 있는 Interval-scaled type - 비율이 있는 Ratio-scaled type |
- 범주(category)로 분류가 가능한 data type - 명목 척도라는 표현으로 사용되기도 함 - 색깔, 학교명, ID, 전공명 등 - 두 개의 Category만 분류할 때는 Binary Type으로 구별 |
- 범주(category)로 분류가 가능하나 범주간의 '순서'가 있음 - 명목 척도라는 표현으로 사용되기도 함 - 측정되는 scale또는 unit은 사람마다 다를 수 있음 - 순서가 있는 것과 배수로 증가하는 개념은 다른 것임에 주의 |
5) 데이터에 관련된 용어

참고자료
'IT > 언어' 카테고리의 다른 글
| [python] 머신러닝을 위한 Python(6); Data Handling - Pandas # 1 (0) | 2020.06.04 |
|---|---|
| [python] 머신러닝을 위한 Python(5) ; Data handling - Numerical Python (0) | 2020.06.04 |
| [python] 머신러닝을 위한 Python(3) (0) | 2020.06.03 |
| [python] 머신러닝을 위한 Python(2) (0) | 2020.06.03 |
| [python] 머신러닝을 위한 Python(1) (0) | 2020.06.03 |