1. 잠재 변수 공간상의 카테고리의 분포
GAN의 이미지 생성을 봤을 때 떠오른 것은 '다양한 숫자(이미지)가 생성됐지만, 어떻게 구분해서 쓸 수 있는거지?'라는 의문이었다. (보통의) GAN은 지도 학습으로 분류되어 있다고 생각했지만, 이것은 어디까지나 이미지가 진짜인가 가짜인가에 대해 지도학습으로, 예를 들어 minist에서는 이미지가 어떤 숫자에 대응하는지를 지도학습으로 학습하는 것은 아니다.
따라서, 생성기(Generator)가 명시적으로 숫자를 구분해서 쓰는 것을 불가능하다. 훈련 이미지의 라벨을 알려주지 않았으니 당연하다. generator에 있어서 1도, 4도, 6도 모른 채, 오로지 훈련 데이터의 분산에 접근할 수 있도록 학습을 반복한다. 결론적으로 generator 자체는 잘 모르지만서도 '무엇인가 1같은 것', 즉 '1을 1답게 하는 특징'은 잠재변수로 채워진다.

generator의 잠재변수공간 z로부터 이미지를 생성한 경우의 이미자 위 그림이다. 잠재변수 z가 취하는 공간 분포에 다른 숫자가 생성된다.
그러나, 예를 들어 숫자의 1을 1답게하는 특징이 공간 z의 어떤 특징의 영역에 모여있다고 보증할 수 있는 것은 아니다. 1을 쓰는 데에는 다양한 방식이 있다. 수직선 하나를 긋는 사람이 있다던지, 위쪽에 접히는 선을 긋는다던지, 아래에 선을 긋는 사람도 있다. 그러므로 z공간을 지정하여 문자를 구분하는 것은 현실적이지 않다.
그보다는 (적어도 나는) 잠재공간 z에 요구하는 성능이 숫자를 구분하는 것은 아니라고 생각한다. 어떤 숫자를 쓰는지에 관계없지 다양한 글 자체의 훈련 데이터를 학습하여, 그 뒤에 글자의 특징을 잠재공간에 맵핑될 것이다. 이렇게 하여, 둥근 글자나 초서체를 구분하거나, 어떤 사람의 글자체와 지슷하게 하거나, 필압을 변경하거나 등을 실현하고 싶은 것이다. 그러기 위해서는 generator의 잠재 변수와 카테고리 정보를 나눠서 고려하고, 대신에 카테고리 정보의 조건화에서 의생성 모델, 식별모델을 생성할 필요가 있다.
2. Conditional GAN
생성한 이미지를 명시적으로 가려 쓰기 위해서는, 훈련할 때에 교사 데이터의 카테고리(라벨) 정보를 이용하는 것이 conditional GAN이다.
요점은 discriminator에는 '지금, 6에 대해 진짜인가 가짜인가 판별하고 있다.'라던가 generator에는 '지금 3이라는 것을 쓰는 조건을 토대로 이미지를 생성하고 있다'라는 것을 가르쳐 줄 필요가 있다. 논문은 링크를 참조하길 바란다.
아이디어는 매우 간단하며, generator과 discriminator의 각 입력에 라벨 정보를 혼합하는 것일 뿐이다. 다른 것을 동일하다. 카테고리 정보를 이용하여 자체의 식별 모델을 만드는 것이 아닌, 어디까지나 진짜인지 가까인지의 식별을 할 뿐이다. 각 GAN의 파생계에 있어서 기본 구성은 변화가 없다.
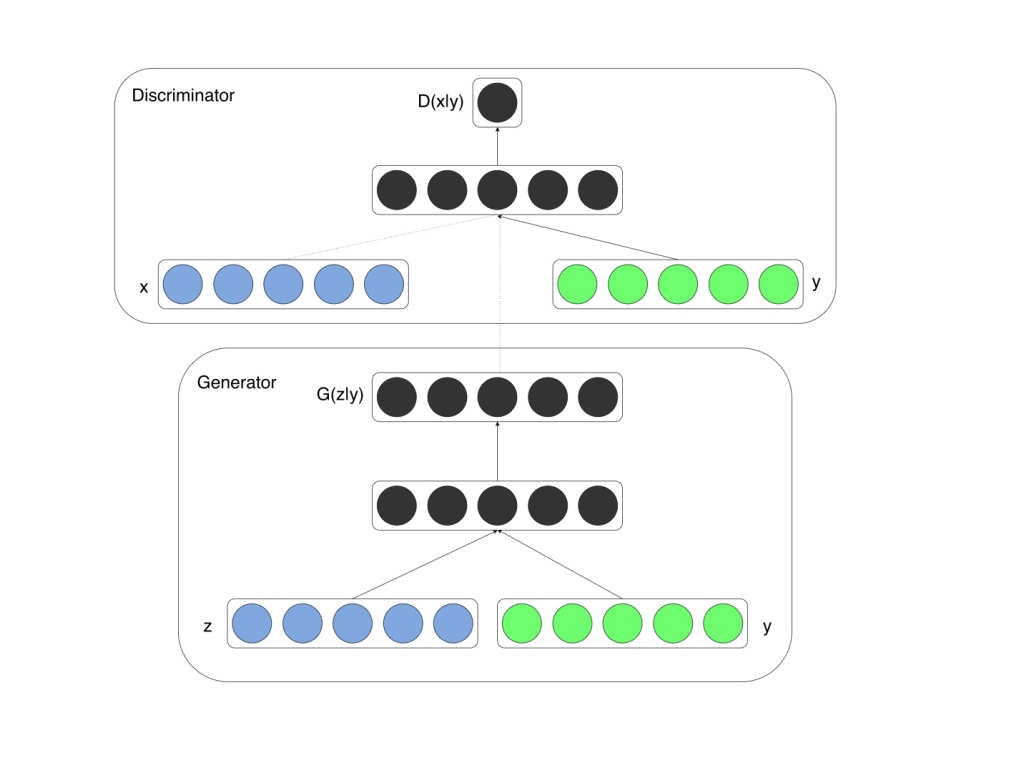
3. Conditional GAN의 구조
1) Generator의 학습시
generator의 학습시에 사용하는 구조는 아래의 그림과 같다. generator 자체로는 학습할 수 없으므로, generator과 discriminator을 연결한 combined 모델을 이용한다.

(1) Generator에 수치 라벨의 입력
Generator에의 입력은 차원수 z_dim의 잠재변수 z이지만, 여기에 라벨 정보를 결합한다. mnist의 경우는 라벨 정보는 수기로 쓴 숫자의 수치인 0~9사이의 숫자이다. 이것을 z에 결합한다. 실제로는 라벨 y는 0~9의 스칼라 값이 아닌, class_num = 10차원을 가진(간략히 말하자면 one_hot) 라벨이다. 이것을 잠재변수와 결합한다.
z와 y의 결합의 방법으로는
① 입력 데이터는 따로 따로 흘려보내, generator 모델 안에서 결합하는 방법
② generator모델 내의 입력 변수는 결합한 사이즈로 하여, 미리 결합한 (하나의) 입력 데이터로 흘려 보내는 방법
의 두 가지를 생각해 볼 수 있다. 이번 구현에서는, 이 두 가지가 혼합되어 있으므로 주의하길 바란다.
모델의 최소단위인 generator과 discriminator에 대해서는 결합한 하나의 데이터가 흘러 들어가는 구조이다. 그 이유는 구조설계의 기본사상으로 데이터 형식을 기본 구조로 변경하고 싶지 않기 때문이다. 그러나, 결한한 입력 데이터를 계속 만들고 있으면 변수의 수가 증가하므로, generator의 학습시에 사용하는 combined 모델에서는 입력 데이터는 따로 따로 넣어 (위의 1), combined_model내에 머지하면서 내부의 generator모델에는 하나의 입력 데이터로 이어가는 형태를 취하고 있다. combined 모델이 데이터 형식의 버퍼로써의 역할을 담당하고 있다고 할 수 잇다.
이러한 방법만 가능한 것은 아니므로, 자신의 취향대로 무엇을 우선으로 할 것인지 정해도 괜찮다고 생각한다. generator의 코드는 아래와 같다.
def build_generator(self):
model = Sequential()
model.add(Dense(input_dim=(self.z_dim + CLASS_NUM), output_dim=1024)) # z=100, y=10
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dense(128*7*7))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Reshape((7,7,128), input_shape=(128*7*7,)))
model.add(UpSampling2D((2,2)))
model.add(Convolution2D(64,5,5,border_mode='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(UpSampling2D((2,2)))
model.add(Convolution2D(1,5,5,border_mode='same'))
model.add(Activation('tanh'))
return model보통의 DCGAN과 상당 다른 점은 input의 차원(사이즈)뿐이다. 잠재변수의 차원수 z_dim에 CLASS_NUM을 더하고 잇다. 클래스 수의 정보가 증가하므로 input의 영역을 넓혀둔다. 이것 뿐이다.
(2) discriminator에의 수치 라벨의 입력
다음은 discriminator에 수치 라벨 정보를 입력하는 것에 대해서 설명한다. discriminator의 입력은 이미지 데이터로 mnist의 경우는 (batch_num, 28, 28, 1)의 행렬이다. (backend = tensorflow표기에)
이미지 데이터에, 수치 라벨 정보를 입력하는 방법으로 매우 단순한 방법이 사용된다. 이미지 데이터는 1채널 (흑백)의 이미지이지만, 여기에 class_num =10종류의 흑백 이미지를 거듭하여 11채널로 한다. 그러나, 정답이 되는 채널의 데이터는 각 픽셀 값이 모든 1의 흰 이미지, 다른 것은 모두 0의 흑백 이미지로 한다. 억지스럽지만 말이다.
예를 들어 라벨이 3인 이미지에 대해서 인덱스 번호3(즉 4장째)만 흰 10장의 이미지를 겹쳐 11채널로 한다. 그림으로 표현하자면 아래와 같다.
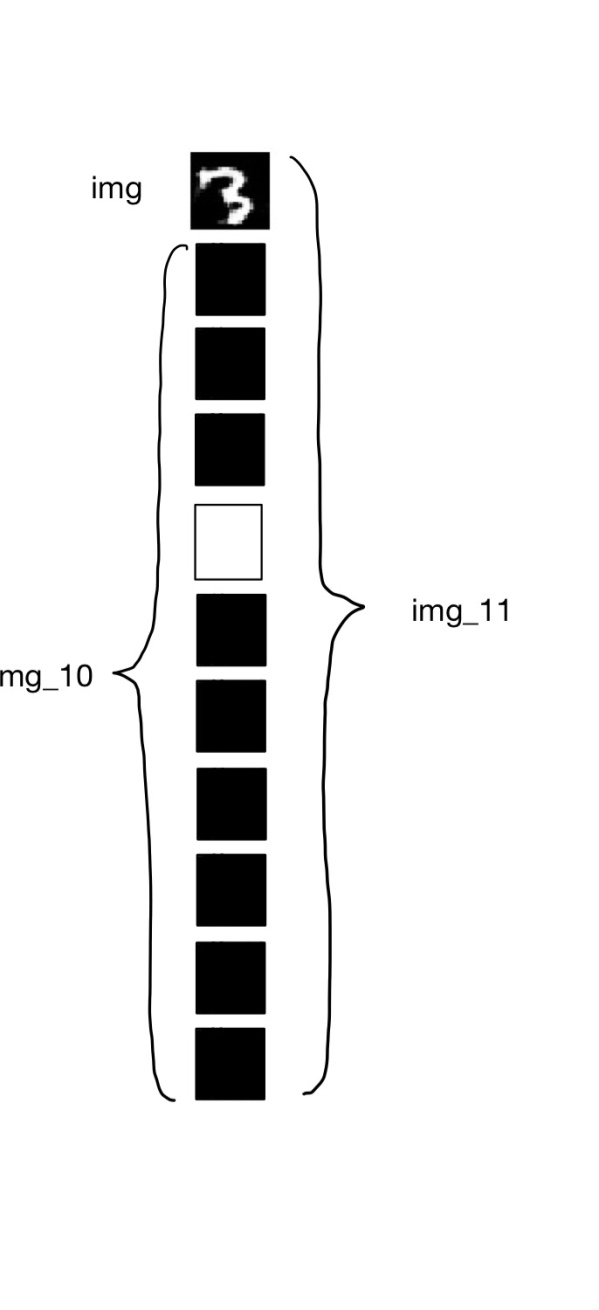
이한 방법을 알았을 때의 정직한 감정은 '아깝네' 이다. 큰 정보도 없는데 이미지의 데이터 양을 11배로 증가시켰으니 말이다. 고해상도 데이터나, 조금 더 큰 카테고리 문제에 대해서는 스케일하지 않는 것은 분명하다. 처리법으로 라벨 정보를 discriminator의 중간층에 입력하는 방법도 효과가 있다. 대단히 참고가 된 블로그는 아래의 링크이다.
http://yusuke-ujitoko.hatenablog.com/entry/2017/10/24/203133
conditional DRAGANでのラベルの与え方 - 緑茶思考ブログ
conditional GANのラベルの与え方は色々あり、 毎回どうすれば良いかよくわからず迷ってしまう。 githubの実装をみると様々に書かれている。 文献を読むよりも色んな人の実装を漁るほうが知見が貯まるこの頃。 今回はMNISTに対してDRAGANを用いて、 その中でもよく見かける設定を評価してみる。 (DRAGANを用いたのは単に安定しているという理由のみ) 以下の設定のもとでいずれの評価も行った. batchsizeは64 optimizerはAdamを使用(learning rate:1e-4
yusuke-ujitoko.hatenablog.com
그러나, 중간층에 라벨 정보를 입력하는 기술은 WGAN-gp에는 사용할 수 없는듯하다(discriminator의 입력값의 평균을 구하므로). GAN의 다(多)카테고리의 적용은 연구중에 있으며, 반드시 좋은 방법이 있다고 생각한다. discriminator의 코드는 아래와 같다.
def build_discriminator(self):
model = Sequential()
model.add(Convolution2D(64,5,5,\
subsample=(2,2),\
border_mode='same',\
input_shape=(self.img_rows,self.img_cols,(1+CLASS_NUM))))
model.add(LeakyReLU(0.2))
model.add(Convolution2D(128,5,5,subsample=(2,2)))
model.add(LeakyReLU(0.2))
model.add(Flatten())
model.add(Dense(256))
model.add(LeakyReLU(0.2))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model이것도 generator의 때와 같이 input을 1채널에서부터 1+class_num(=11)로 변경한 것일 뿐이다.
(3) combined 모델의 작성
generator에서는 위에 설명한대로 z,y 두 값의 인풋을 정의한다. 이것을 모델 내부에 머지한 것이 (z_y)이다. 머지한 변수 z_y를 generator을 통해 가짜 이미지를 생성하는 데이터의 흐름을 만든다(img). 라벨정보로부터 10채널 이미지의 변환은 label2images함수를 사용한다.
생성한 가짜 데이터와 라벨 정보를 10cn이미지로 한 (img_10)을 머지한다(img_11). 이것을 discriminator을 통한 것이 최종 출력이다. 모델의 입력 변수는 z, y, img_10이다.
def build_combined(self):
z = Input(shape=(self.z_dim,))
y = Input(shape=(CLASS_NUM,))
img_10 = Input(shape=(self.img_rows,self.img_cols,CLASS_NUM,))
z_y = merge([z, y],mode='concat',concat_axis=-1)
img = self.generator(z_y) # [batch, WIDTH, HEIGHT, channel=1]
img_11 = merge([img, img_10],mode='concat', concat_axis=3)
self.discriminator.trainable= False
valid = self.discriminator(img_11)
model = Model(input = [z, y, img_10], output = valid)
return model2) Discriminator의 학습시
discriminator학습시의 구조는 아래와 같다.

기존은 GAN의 설명과 변화가 없다. generator은 이미지를 생성하기 위한 것이다. 실데이터를 미리 결합(np.ndarray의 결합이므로 np.concatenate를 이용한다) 한 후부터, discriminator에 돌입한다. 이번에도 가짜의 이미의 생성 데이터와 실제 데이터를 동시에 입력시킨다.
4. 생성결과
생성결과는 아래와 같다. 0, 1, 2, 3,...과 지정한 이미지를 생성해간다. 잠재변수의 값은 각 매스 다르다. 라벨을 붙여 숫자를 나눠 쓰는데 성공하고 있다.

5. 마무리
- Conditional GAN을 이용하여 라벨 정보를 전달하면서 GAN를 학습시킨다.
- Generator에 라벨 정보를 전달하며 생성해 문자를 나눠 쓰는 것이 가능하다.
전체 코드는 아래의 github를 참고하길 바란다.
https://github.com/triwave33/GAN/blob/master/GAN/cgan/cgan_mnist.py
triwave33/GAN
Contribute to triwave33/GAN development by creating an account on GitHub.
github.com
참고문헌
https://qiita.com/triwave33/items/f6352a40bcfbfdea0476
'IT > AI\ML' 카테고리의 다른 글
| GAN ; 잠재 변수와 생성 이미지 (0) | 2020.05.01 |
|---|---|
| [논문] GAN ; CycleGAN (Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks) (2) | 2020.04.30 |
| [python] PCA와 ICA의 개요와 차이점 (2) | 2020.04.30 |
| Manifold Learning(多様体学習)과 알고리즘 (0) | 2020.04.30 |
| [python/Keras] GAN ; pix2pix (0) | 2020.04.28 |