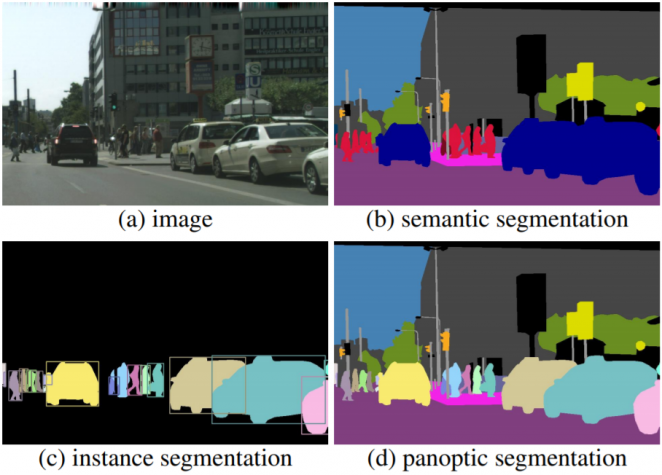
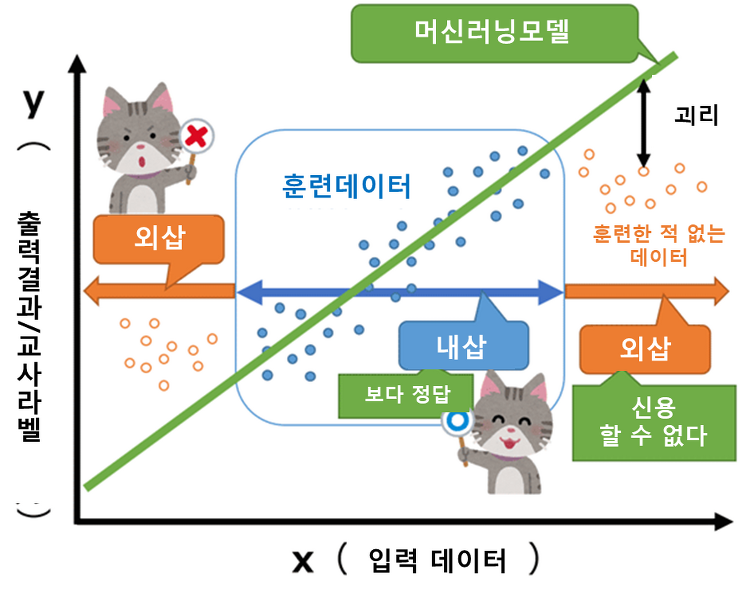
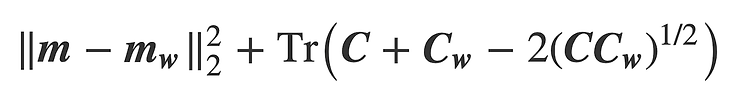※ 일본의 한 블로그 글을 번역한 포스팅입니다. 오역 및 의역, 직역이 있을 수 있으며, 틀린 내용은 지적해주시면 감사하겠습니다. 이번 포스팅에서는 지난 포스팅에 이어 실제로 Azure에서 MLOps를 구현해보고자 한다. Azure에서 MLOps 라이프 사이클을 실현하기 위한 최적화된 방법 아래 5개의 그림이 Azure에서 추천하는 MLOps기반의 좋은 방법이다. 1. 재이용 가능한 파이프라인으로 모델을 만들기 모델링에 이용하는 데이터 세트의 선택, 각 종 파라미터의 설정등도 하나로 모아서 모델 생성의 포르레스를 파이프라인화한다. 2. 모델 등록의 자동화 이벤트 구동형으로 실제 사용자 환경에 가동할 모델을 바꿀 수 있도록 메타 정보를 포함하여 모델의 버전 관리를 행한다. 3. 감사증좌의 자동화 테스트 코..