머신러닝이나 예측 분석(데이터 마이닝등)에 있어서 Dritf이란 어떠한 "예측하지 못한 변화"에 의해 모델의 예층 성능이 시간이 경과함에 따라 떨어지는 것을 일컫는다. Model drift나 Model decay(모델의 쇠퇴), Model staleness(모델의 진부) 등으로 불리는 듯하다. 드리프트가 발생하는 원인마다 다양한 관련 용어가 정의되어 있으며, 주된 용어로 Concept drift와 Data drift가 있다.
Concept drift란, 입력 데이터(특징량, 설명변수)에서 부터 예측하려고 하는 "정답 라벨(목적 변수)"의 의미/개념/통계적 특성(즉 데이터와 라벨의 관계성, 데이터의 해석 방법)이 모델 훈련때와 비교하여 변화가 있음을 의미한다.
Data drift란, 모델의 훈련시 "입력 데이터(특징량, 설명변수)"의 통계적 분포와 테스트 시/ 실제 배포 환경에서의 "입력 데이터"의 통계적 분포가 어떠한 변화에 의해 차이가 발생하고 있는 것을 의미한다. Feature drift나 Covariate shift라고 불린다.
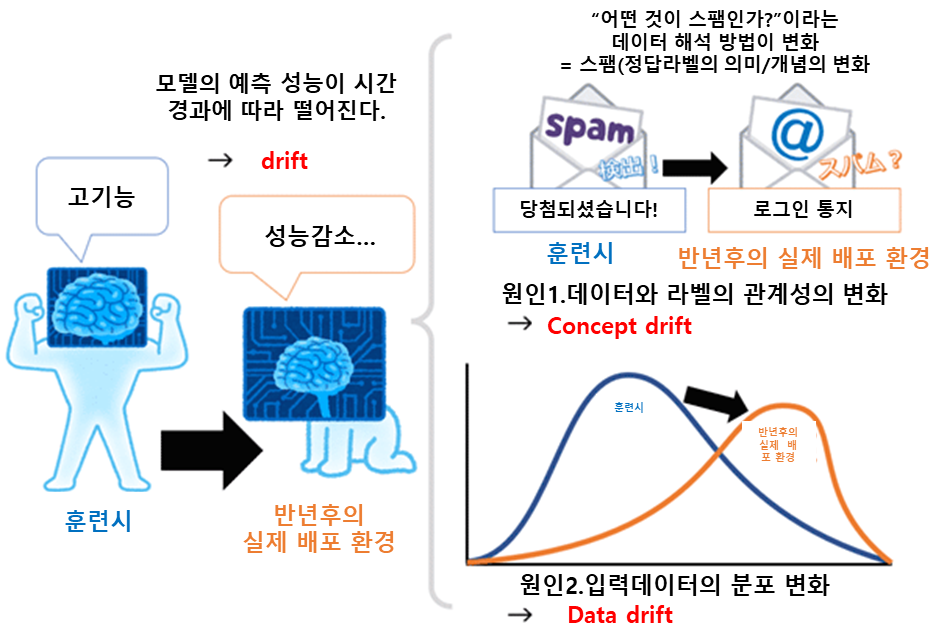
Concept drift의 예를 하나 들자면, SNS에서 스팸을 검출하는 머신 러닝 모델을 운용을 시작해, 맨 처음에는 높은 정답률으로 검출했지만, 반녀 후에는 거의 검출 못하게 됐다. 이 원인이 스팸 메시지를 보내는 쪽에서 새로운 스팸 방법을 고안해낸 것이다 (입력 데이터의 분포는 변화하지 않았을 경우). 즉 drift의 원인은 정답 라벨(목적 변수)인 스팸의 개념이 변화했다는 것이다.
Data drift의 예는 SNS에 아침일찍 투고하는 사람이 스팸을 보내는 사람으로 검출하도록 학습한 머신러닝모델의 운용을 시작해, 맨 처음에는 높은 정답률을 검출해냈지만, 반년 후에는 일반 사람을 스팸을 보내는 사람으로 오검출하게 됐다. 이러한 원인으로 최근에 시니어 층의 SNS이용이 늘어 이른 아침에 투고하는 사람이 많아졌기 때문이다(스팸의 개념은 변화하지 않았을 경우). 즉 drift의 원인은 입력 데이터의 분포가 훈련때와 실제 환경에서 변화한 것이다.
이러한 Concept drift와 Data dritf이외에도 예를 들어 아래와 같은 drift관련 용어가 정의되어 있다.
- Lable drift : "정답 라벨(타겟변수)"의 통계적 분포에 무언가 변화 생긴 것을 의미한다. Target Shift로 불린다.
- Prediction drift : 실제 배포 환경에서의 "예측값"의 통계적 분포에 무언가 변화가 생겨, 데이터와 예측값의 관계성이 변화가 생긴 것을 의미한다. 이것은 Concept drift의 시그널이 될 가능성이 있다.
또한, 각 drift는 배타적이지 않고, 여러 개의 drift가 동시에 발생하는 경우가 있다.
참고자료
https://atmarkit.itmedia.co.jp/ait/articles/2202/21/news033.html
'IT > AI\ML' 카테고리의 다른 글
| 머신러닝 구현 속도를 올려주는 VSCode 설정 (0) | 2022.04.14 |
|---|---|
| [python] AI엔지니어가 주의해야할 python 코드 작성 포인트 (0) | 2022.04.13 |
| segmentation의 종류 (semantic segmentation, instance segmentation, panoptic segmentation의 차이) (0) | 2022.03.31 |
| GAN의 평가지표 FID(Frechet Inception Distance)와 PPL(Perceptual Path Length) (0) | 2022.02.28 |
| 머신러닝에서의 내삽(보간, Interpolation), 외삽(보외, Extrapolation) (0) | 2022.02.28 |