딥 러닝의 학습 효율이나 머신의 비용을 고려해봤을 때, 조금이라도 학습 시간을 단축하고 싶을 것이다. 이 때 사용할 수 있는 것이 Tensorflow Profiler이다. 이번 포스팅에서 MNIST 데이터 세트를 이용한 간략한 Tensorflow Profiler의 사용법에 대해서 알아보고자 한다.
Tensorflow Profiler이란?
Tensorflow Profiler는 TensorFlow의 계산시에, 처리마다 소요시간등 퍼포먼스 정보를 수집해서, TensorBoard상에 가시화해주는 툴이다. Tensorflow v2.2.0이나 Tensorflow 2.3.0에서 기능이 강화되어 보다 상세한 분석이 가능해졌다.
Tensorflow Profiler 설치
Tensorflow Profiler을 이용하기 위해서는 일반적인 Tensoflow 외에 추가라이브러리인 tensorboard-plugin-profile를 설치할 필요가 있다. 설치는 아래의 커맨드로 가능하다. 버전의 경우, 설치를 원하는 버전으로 바꿔서 실행하면 된다.
$ pip3 install tensorflow==2.3.0
$ pip3 install tensorboard==2.3.0
$ pip3 install tensorboard-plugin-profile==2.3.0
MNIST 학습 분석
검증을 위해, MNIST이라는 Deep Learing에서 친숙한 데이터 세트를 학습시키고자 한다. Tensorflow Profiler를 사용하기 위해서는 tf.keras.callbacks.TensorBoard의 인수 profile_batch에 프로파일 정보를 얻을 기간을 설정한다.
import os
import datetime
import tensorflow as tf
import tensorflow_datasets as tfds
from absl import logging
def normalize_image(image, label):
return tf.cast(image, tf.float32) / 255., label
def build_dataset(split, batch_size):
dataset, ds_info = tfds.load('mnist', split=split,
as_supervised=True,
with_info=True)
dataset = dataset.map(normalize_image)
dataset = dataset.batch(batch_size)
if split == 'train':
dataset = dataset.repeat()
dataset = dataset.shuffle(100)
num_examples = ds_info.splits[split].num_examples
return dataset, num_examples
def build_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
return model
def train_with_fit(model, optimizer, loss_fn,
epochs, steps_per_epoch, ds_train, ds_test,
log_dir, profile_start_step, profile_end_step):
model.compile(
optimizer=optimizer,
loss=loss_fn,
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
# 프로파일 설정
tboard_callback = tf.keras.callbacks.TensorBoard(
log_dir=log_dir,
profile_batch=[profile_start_step, profile_end_step])
model.fit(ds_train,
epochs=epochs,
callbacks=[tboard_callback],
validation_data=ds_test,
steps_per_epoch=steps_per_epoch)
def main():
epochs = 10
batch_size = 128
log_dir = './logs'
profile_steps = 20
ds_train, num_train = build_dataset(split='train', batch_size=batch_size)
ds_test, num_test = build_dataset(split='test', batch_size=batch_size)
steps_per_epoch = num_train // batch_size
profile_start_step = int(steps_per_epoch * 1.5)
profile_end_step = profile_start_step + profile_steps
model = build_model()
optimizer = tf.keras.optimizers.Adam()
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
log_dir = os.path.join(log_dir,
datetime.datetime.now().strftime('%Y%m%d-%H%M%S'))
train_start = datetime.datetime.now()
train_with_fit(model, optimizer, loss_fn,
epochs, steps_per_epoch, ds_train, ds_test,
log_dir, profile_start_step, profile_end_step)
train_sec = datetime.datetime.now() - train_start
logging.info(f'Train sec: {train_sec}')
if __name__ == '__main__':
logging.set_verbosity(logging.INFO)
main()이 코드 실행 결과 10 에포크의 학습에 17.732초가 걸렸다.
Tensorflow Profiler에 의해 지정된 학습 스텝간의 프로파일 정보가 수집되어, 각 처리마다 계산시간이 가시화된다. 이로 인해, 스텝마다 평균 시간이 3.4 밀리초 걸린다는 사실을 알 수 있다. 더욱이 프로파일의 결과를 바탕으로 개선안이 화면에 표시된다. 이러한 개선안을 시험해보고자 한다.

입력 파이프라인의 최적화
먼저 전체의 55%를 소비하고 있는 입력 파이프라인 최적화를 위해, build_dataset 함수를 수정한다. 또한, 이 입력 파이프라인의 최적화에 대해서는 Tensorflow Profiler튜토리얼에 기재되어 있듯, Tensorflow Profiler에서는 약속되어 있는 내용인듯하다.
def build_dataset(split, batch_size):
dataset, ds_info = tfds.load('mnist', split=split,
as_supervised=True,
with_info=True)
dataset = dataset.map(
normalize_image,
num_parallel_calls=tf.data.experimental.AUTOTUNE) # 추가
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE) # 추가
if split == 'train':
dataset = dataset.repeat()
dataset = dataset.shuffle(100)
num_examples = ds_info.splits[split].num_examples
return dataset, num_examples실행 결과, 학습시간이 10.239표로 단축되었다. 또한, 1스텝마다 평균시간이 1.7밀리초 감소됐다.

계속해서 GPU 스레드 점유화를 시험해보자.
GPU 스테드의 점유화
GPU 스레드의 점유화는 환경변수를 TF_GPU_THREAD_MODE=gpu_private로 설정한다.
def main():
os.environ['TF_GPU_THREAD_MODE'] = 'gpu_private' # 추가
(이하 생략)실행 결과, 학습시간이 9. 852초로 단축됐고, 1스텝마다 평균 시간이 1.5밀리초 감소됐다.

여기까지 순조롭게 학습시간을 단축시켰다. 다음은 혼합 정밀도를 이용하여 32bit계산을 16bit계산으로 바꿔보자.
혼합 정밀도
혼합 정밀도는 float32 대신에 float16를 이용해 계산하는 것으로, 메모리를 절감할 수 있다. 더욱이 이번에 사용하고 있는 일부의 GPU, TPU로 계산 속도 향상이 될 것으로 보인다.
from tensorflow.keras.mixed_precision import experimental as mixed_precision #추가
def build_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10), # activation
tf.keras.layers.Activation('softmax', dtype='float32') # 추가
])
return model
def main(args):
os.environ['TF_GPU_THREAD_MODE'] = 'gpu_private'
epochs = 10
batch_size = 128
log_dir = './logs'
profile_steps = 20
ds_train, num_train = build_dataset(split='train', batch_size=batch_size)
ds_test, num_test = build_dataset(split='test', batch_size=batch_size)
steps_per_epoch = num_train // batch_size
profile_start_step = int(steps_per_epoch * 1.5)
profile_end_step = profile_start_step + profile_steps
policy = mixed_precision.Policy('mixed_float16') # 추가
mixed_precision.set_policy(policy) # 추가
model = build_model()
optimizer = tf.keras.optimizers.Adam()
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy()
(이하 생략)Tensorflow Profiler화면 왼쪽 아래에 16bit 계산과 32bit계산의 비율이 표시되어 있다. 혼합 정밀도를 도입한 결과, 29.6%를 16bit 계산으로 바꾸는 것이 가능하게 됐다. 그러나 아쉽게도, 학습시간은 12.601초, 1스텝마다 평균 2.4밀리초로 각각 늘어났다.
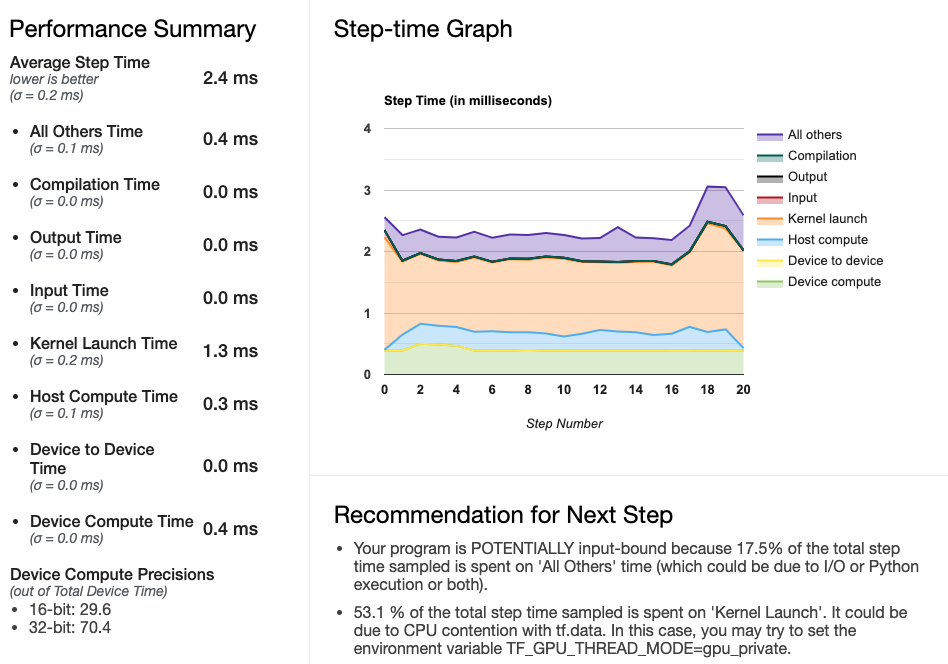
혼합 정밀도의 도입 결과는 좋지 않았기 때문에 무효화하고 다음은 커스텀 훈련 루프를 실험해보도록 한다.
커스텀 훈련 루프
Keras fit 함수의 대신에, 커스텀 훈련 루프를 사용한다. TensorBoard 콜백을 설정했을 뿐인 Keras fit과 달리, tf.profiler.experimental.start, tf.profiler.experimental.stop, tf.profiler.experimental.Trace로 프로파일 데이터의 획득을 제어할 필요가 있다. train_with_fit 대신이 될 train_with_cutom_loop를 작성해보자.
def train_with_custom_loop(model, optimizer, loss_fn,
epochs, steps_per_epoch, ds_train, ds_test,
log_dir, profile_start_step, profile_end_step):
train_loss = tf.keras.metrics.Mean()
train_acc = tf.keras.metrics.SparseCategoricalAccuracy()
val_loss = tf.keras.metrics.Mean()
val_acc = tf.keras.metrics.SparseCategoricalAccuracy()
@tf.function
def train_step(X, y_true):
with tf.GradientTape() as tape:
y_pred = model(X)
loss = loss_fn(y_true, y_pred)
graidents = tape.gradient(loss, model.trainable_weights)
optimizer.apply_gradients(zip(graidents, model.trainable_weights))
train_loss.update_state(loss)
train_acc.update_state(y_true, y_pred)
return loss
@tf.function
def validation_step(X, y_true):
y_pred = model(X)
loss = loss_fn(y_true, y_pred)
val_loss.update_state(loss)
val_acc.update_state(y_true, y_pred)
return loss
global_step = optimizer.iterations.numpy()
summary_writer = tf.summary.create_file_writer(log_dir)
train_iter = iter(ds_train)
total_steps = epochs * steps_per_epoch
logging_interval = math.ceil(steps_per_epoch / 20)
with summary_writer.as_default():
for global_step in range(global_step, total_steps):
if global_step == profile_start_step:
tf.profiler.experimental.start(log_dir)
logging.info(f'Start profile at {global_step}')
elif global_step == profile_end_step:
tf.profiler.experimental.stop()
logging.info(f'End profile at {global_step}')
with tf.profiler.experimental.Trace('train',
step_num=global_step, _r=1):
X, y_true = next(train_iter)
train_step(X, y_true)
if (global_step + 1) % logging_interval == 0:
logging.info(f'Steps: {global_step}, '
f'Train Acc: {train_acc.result():.3f}, '
f'Train Loss: {train_loss.result():.3f}')
tf.summary.scalar(
'Train/Acc', data=train_acc.result(), step=global_step)
tf.summary.scalar(
'Train/Loss', data=train_loss.result(),
step=global_step)
train_loss.reset_states()
train_acc.reset_states()
if ((global_step + 1) % steps_per_epoch == 0 or
global_step == total_steps - 1):
for X, y_true in ds_test:
validation_step(X, y_true)
logging.info(f'Steps: {global_step}, '
f'Val Acc: {val_acc.result():.3f}, '
f'Val Loss: {val_loss.result():.3f}')
tf.summary.scalar(
'Val/Acc', data=val_acc.result(), step=global_step)
tf.summary.scalar(
'Val/Loss', data=val_loss.result(), step=global_step)
val_loss.reset_states()
val_acc.reset_states()
def main():
(생략)
train_start = datetime.datetime.now()
# `train_with_fit`에서 바꿔 작성
train_with_custom_loop(model, optimizer, loss_fn,
epochs, steps_per_epoch, ds_train, ds_test,
log_dir, profile_start_step, profile_end_step)
train_sec = datetime.datetime.now() - train_start
logging.info(f'Train sec: {train_sec}')실행 결과, 학습 시간이 9.534초로 짧아지고 학습 도중에 스파이크가 보이긴하지만, 1스텝 평군 1.4초로 감소됐다.
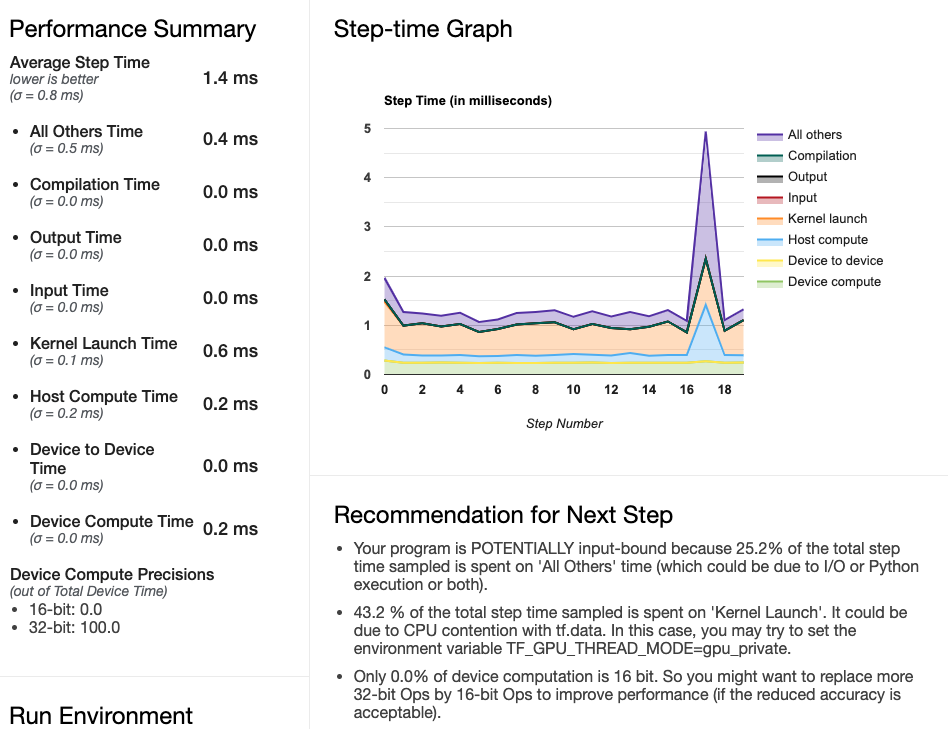
실험 결과의 정리
패턴마다 학습시간을 정리하자면 다음과 같다. 가장 학습시간이 짧은 것은 커스텀 훈련 루프에 입력 최적화와 GPU 스레드 점유화를 적용한 조합이다.
| 실험 | 학습방법 | 입력 최적화 | GPU 스레드 점유화 |
혼합 정밀도 | 학습 시간 | 1스텝 평균 시간 |
검증 정밀도 |
| 1 | Keras fit | - | - | - | 17.732초 | 3.4밀리초 | 97.54% |
| 2 | Keras fit | O | - | - | 10.239초 | 1.7밀리초 | 97.62% |
| 3 | Keras fit | O | O | - | 9.852초 | 1.5밀리초 | 97.80% |
| 4 | Keras fit | O | O | O | 12.601초 | 2.4밀리초 | 97.70% |
| 5 | Keras fit | O | O | - | 9.534초 | 1.4밀리초 | 97.80% |
이번에 사용한 전체 코드는 여기서 확인 가능하다.
참고자료
https://tech.unifa-e.com/entry/2020/09/08/120450
'IT > AI\ML' 카테고리의 다른 글
| [python/Tensorflow1.x] Tensorflow의 이름공간(NameSpace)와 공유 변수(Sharing Variable) (0) | 2022.01.12 |
|---|---|
| [python] 결정계수 R2와 자유도 조정 결정 계수 R*2 (0) | 2021.11.28 |
| [python/tensorflow2.x] Tensorflow2.x버전 작성법(2) (0) | 2021.09.14 |
| [python/tensorflow2.x] Tensorflow2.x버전 작성법(1) (0) | 2021.09.11 |
| [python] 데이터 사이언티스트(데이터 분석가)에 도움이 되는 Tip : yield, partial, map, filter, reduce, enumerate (0) | 2021.08.03 |