Model클래스의 서브 클래스화 [tf.kera-Subclassing/Imperative API]
이 방법은 전 포스팅의 Functional API와 공통되는 부분이 많다. 구체적으로 먼저 class NeuralNetwork(tf.keras.Model):이라는 코드(NeuralNetwork 클래스)를 추가적으로 작성하면 끝이다. 아래의 코드를 살펴보자.
# ### 활성화 함수를 변수(하이퍼 파라미터)로써 정의 ###
# 변수(모델 정의시에 필요로하는 수치)
activation1 = layers.Activation('tanh' # 활성화 함수(은닉층용): tanh함수(변경 가능)
, name='activation1' # 활성화 함수에 이름 붙이기
)
activation2 = layers.Activation('tanh' # 활성화 함수(은닉층용): tanh함수(변경 가능)
, name='activation2' # 활성화 함수에 이름 붙이기
)
acti_out = layers.Activation('tanh' # 활성화 함수(출력층용): tanh함수(고정)
, name='acti_out' # 활성화 함수에 이름 붙이기
)
# tf.keras.Model를 서브 클래스화하여 모델을 정의
class NeuralNetwork(tf.keras.Model):
# ###레이어를 정의 ###
def __init__(self, *args, **kwargs):
super(NeuralNetwork, self).__init__(*args, **kwargs)
# 입력층 정의는 불필요하다.실제 입력에 따라 결정되기 때문이다.
# 은닉층:첫 번째 레이어
self.layer1 = layers.Dense( # 전결합층
#input_shape=(INPUT_FEATURES,), # 입력층(정의 불필요)
name='layer1', # 표시용으로 이름을 붙임
units=LAYER1_NEURONS) # 유닛 수
# 은닉층:두 번째 레이어
self.layer2 = layers.Dense( # 전결합층
name='layer2', # 표시용으로 이름을 붙임
units=LAYER2_NEURONS) # 유닛 수
# 출력층
self.layer_out = layers.Dense( # 전결합층
name='layer_out', # 표시용으로 이름을 붙임
units=OUTPUT_RESULTS) # 유닛 수
# ### 순전파 경로를 정의 ###
def call(self, inputs, training=None): # 입력과, 훈련, 평가 모드
# 「출력=활성화함수(제n층(입력))」의 형식으로 기재
x1 = activation1(self.layer1(inputs)) # 활성화 함수는 변수로써 정의
x2 = activation2(self.layer2(x1)) # 위와 동일
outputs = acti_out(self.layer_out(x2)) # ※활성화 변수는「tanh」고정
return outputs
# ### 모델의 생성 ###
# model = tf.keras.Model(inputs=inputs, outputs=outputs
# , name='model_constructor' # 모델에도 이름을 붙임
# )
model = NeuralNetwork() # 모델의 생성
# ### 아래에서 모델 설계를 완료 ###
#model.summary() # 모델 내용의 출력이 안된다! (뒤에서 설명)독자의 NeuralNetwork 클래스를 추가한 후에, "레이어를 정의"하는 코드군은 컨스트럭터가 되는 __init__()메소드 내에 정리하고, (순전파의) 순전파 패스를 정의하는 코드군은 def call(self, inputs) 메소드에 정의하고 있다. 메소드화하는 것으로, self. 나 return outputs이라는 코드가 필요하게 됐다. 순서를 정리하자면 다음과 같다.
1. tf.keras.Model 클래스로부터 파생된 독자적인 서브 클래스(NeuralNetwork 클래스)를 기재
2. __init__()메소드 안에 "레이어를 정의"
3. def call(self, inputs): 메소드내에 "순전파 패스를 정의"
이 두 개의 메소드는 적당한 타이밍에 자동적으로 호출되는 구조로 되어 있다.
한편, 세 번째, def call(self, inputs, training)와 같이 인수 training을 추가하는 것도 가능하다. 이 인수는 훈련시의 호출인가(True), 정밀도 검증(=평가)시의 호출인가(False)에 따라 처리를 구분하는데에 이용할 수 있다. 예를 들어 평가시에는 Dropout처리를 무효화하는 것 등과 같은 경우말이다. training의 값은 모델의 추론시에 지정할 수 있으므로 뒤에서 다시 한 번 설명하겠다.
이전 포스팅의 Funtional API와 비교하자면, 입력층을 기재하는 부분이 없다. 이것은 def call(self, inputs) 메소드의 인수 inputs에 실제의 Tensorflow텐서 데이터가 들어오므로, 별 다른 준비를 할 필요가 없다.
이상, Funtional API와 비교하면 확실히 코드의 수가 늘어났지만, 코드를 읽기 쉬워졌다고 할 수 있다.
모델의 내용과 구성도의 출력에 대해
위 코드의 마지막 행 model.summary()이라는 코드에 대해 주석에 기재했지만, 실행하면 에러가 발생한다.
model.summary() # 에러! ← 계싼 그래프가 구축되지 않은 상태이므로
# 츨력되는 에러 예
# ValueError: This model has not yet been built. Build the model first by calling `build()` or calling `fit()` with some data, or specify an `input_shape` argument in the first layer(s) for automatic build.이전 포스팅에서 설명했던 Sequentail 모델이나, Funtional API는 선언형(Define-and-Run)이므로 모델을 정의&인스턴스화한 단계에서 계산 그래프가 정적으로 구축된다. 한편 Subclassing 모델은 명령형(Define-by-Run)이므로 실행한 단계에서 계산 그래프가 동적으로 구축되는 사양이다.
즉, 아직 실행하고 있지 않으므로, 계산 그래프가 구축되어있지 않아, 모델의 내용과 구성도가 출력되지 않은 것이다. 그렇다면 추론을 1회 실행하여, 계산 그래프를 동적으로 작성하면 제대로 동작할 것이다.
model1 = NeuralNetwork(name='subclassing_model1') # 모델의 생성
# 방법1: 추론하여 동적으로 그래프를 구축
temp_input = [[0.1,-0.2]] # 임의의 입력치
temp_output = model1.predict(temp_input) # 추론의 실행
# 모델의 입력을 출력
model1.summary()
# 모델의 구성도를 표시
tf.keras.utils.plot_model(model, show_shapes=True, show_layer_names=True, to_file='model.png')
from IPython.display import Image
Image(retina=False, filename='model.png')Subclassing 모델의 추론 방법에 대해서는 뒤에서 설명하겠지만, 위 코드에서는 지금까지와 동일하게, predict() 메소드를 사용하여 추론하고 있다. 그 결과 아래의 그림과 같이 모델 내용와 구성도의 출력을 얻어낼 수 있다.


출력에서 신경쓰이는 점이 구성도가 제대로 출력되지 않는다는 것이다. 모델의 생성시에 인수 name에 지정한 이름도 반영되지 않았다. 이 방법을 이용한 구성도 출력은 더 이상 사용하지 못한다고 할 수 있다.
다른 방법은 없는걸까? 앞에서 언급한 에러 발생예에 "build()를 호출할 것인가"라고 기재되어 있었다. 여기서 build()메소드를 호출해 보면 다음과 같다.
model2 = NeuralNetwork(name='subclassing_model2') # 모델의 생성
# 방법2: 입력 형태를 지정하여 계산 그래프를 구축한다.
model2.build( # 모델의 빌드
input_shape=(None,2)) # 입력의 형태(=입력층)※튜플형식
# 모델의 내용을 출력
model2.summary()
# 모델의 구성도를 표시
tf.keras.utils.plot_model(model2, show_shapes=True, show_layer_names=True, to_file='model.png')
from IPython.display import Image
Image(retina=False, filename='model.png')build() 메소드에서는 인수 input_shape인수의 지정가 필수이다. input_shape에는 (미니 배치 사이즈, 입력 데이터 차원)의 형태로 지정한다. "미니 배치 사이즈"는 애매하므로 None으로 하였다. "입력 데이터 차원"은 X좌표와 Y좌표 두 개이므로 2로 지정하였다.
그 결과 모델 내용과 구성도가 출력됐다.


모델의 생성시에 인수 name에 지정했던 이름은 반영되었음을 알 수 있으나 두 번째의 방법에서도 모델의 구성도를 제대로 출력하고 있지 않다는 것을 알 수 있다. Subclassing모델의 기본 기능에서는 이러한 제약이 있다.
그러나, 요령을 사용하면 예를 들면, Funtional API와 동일하게 자세한 모델 내용과 구성도를 출력하는 것도 가능하다.
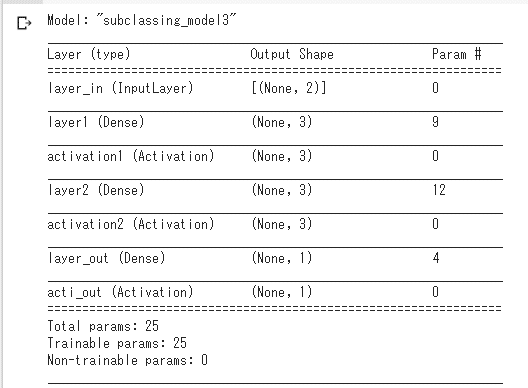
model3 = NeuralNetwork() # 모델의 생성
# 「임의의 모델」을Functional API로 생성하는 독자함수
def get_functional_model(model):
# 이 코드는「이전 포스팅의 Functional API」와 거의 동일
x = layers.Input(shape=(INPUT_FEATURES,), name='layer_in')
temp_model = tf.keras.Model(
inputs=[x],
outputs=model.call(x), # ※서브 클래스화한 모델의 'call'메소드를 지정
name='subclassing_model3') # 임의의 모델에도 이름을 붙인다.
return temp_model
# Functional API의「임의의 모델」을 취득
f_model = get_functional_model(model3)
# 모델의 내용을 출력
f_model.summary()
# 모델의 구성도를 표시
tf.keras.utils.plot_model(f_model, show_shapes=True, show_layer_names=True, to_file='model.png')
from IPython.display import Image
Image(retina=False, filename='model.png')위 코드에서 하고 있는 것은 Subclassing모델에서 작성한 모델(model3)을 베이스로, Funtional API의 모델로써 재구성한 "임의의 모델"(f_model)를 사용하여, 그 내용과 구성도를 출력하는 동작이다.
Funtional API화되어 있으므로, 당연하지만, 자세한 정보가 출력될 수 있다. 또한, 공식으로 설명되어 있는 방법은 아니다.

이상으로, Model 클래스의 서브 클래스화의 설명은 끝이다. 그러나 학습과 추론에 대해서는 설명을 생략했었다. 지금까지는 Sequentail 모델과 동일하게 기재하는 것이 가능했지만, 보다 전문가용 작성법이 있으므로, 조금 길어지지만 아래에서 설명하도록 하겠다.
학습과 추론 : 작성법 입문(전문가용)
초중급자용 작성법의 복습
먼저 Sequential 모델에서 소개한 "학습과 추론 작성법"을 복습해 두자. 아래의 코드는 이전의 포스팅에 봤던 코드와 동일한 것이다. 설명은 이전에 했으므로 생략하겠다.
# 학습 방법을 설정하고, 학습, 추론(예측)한다.
model.compile(tf.keras.optimizers.SGD(learning_rate=0.03), 'mean_squared_error', [tanh_accuracy])
model.fit(X_train, y_train, validation_data=(X_valid, y_valid), batch_size=15, epochs=100, verbose=1)
model.predict([[0.1,-0.2]])이 코드와 비교하여 전문자용 작성법은 어떻게 다른지 살펴보자.
추론
먼저 간단히 사용할 수 있는 "추론"부터 설명하겠다.
# 【초중급자용과 비교용】추론한다.
# python_input2 = [[0.1,-0.2]]
# predict2 = model.predict(python_input2)
# print(predict2)
# # [[0.9845763]] ……등으로 표시된다.
# ###【전문가용】추론한다. ###
python_input1 = [[0.1,-0.2]] # 입력 값(Python리스트값/NumPy다차원 배열값)
# Python리스트 값이나 NumPy다차원 배열값은 텐서로 변환할 필요가 있다.
tensor_input1 = tf.convert_to_tensor(python_input1, dtype=tf.float32)
#tensor_input1 = tf.constant([[0.1,-0.2]]) # 입력값(정수)
#tensor_input1 = tf.Variable([[0.1,-0.2]]) # 입력값(변수)
predict1 = model(tensor_input1) # ※텐서 입력밖에 받을 수 없다.
print(predict1) # ※텐서가 출력된다.
# tf.Tensor([[0.9845763]], shape=(1, 1), dtype=float32) ……등과 표시된다.추론(예측: predict)를 실행하고 있는 부분은 predict1 부분이다. model.predict() 메소드의 호출이지만, model()이라는 호출로 변경된 것을 주목했음 한다. model은 NeuralNetwork 클래스의 오브젝트이지만, 함수와 같이 호출하면, 클래스 내부에 있는 __call()__ 특수 메소드가 호출되는 구조이다. 이 __call__()특수 메소드는 내부에서 call()메소드를 호출하는 것으로, 순전파가 실행되어 예측값이 계산된다 (=추론).
주의점으로는 tf.keras기능의 predict()메소드는 Python리스트값이나 NumPy 다차원 배열값 입력을 받아 출력한다. 한편, model()함수는 TensorFlow텐서를 입력을 받아 출력하는 것과 다르다는 점이다. 즉, 전문가용의 model()함수의 쪽이 보다 TensorFlow 내부에 가까운 처리라는 것이다.
TensorFlow 텐서의 취득방법으로써는 아래의 3개의 방법가 코드에 포함되어 있으므로 확인해두자.
1. tf.convert_to_tensor() 함수 : Python 리스트 값/ NumPy 다차원 배열 값을 TensorFlow 텐서로 변환
2. tf.constant() 클래스의 컨스트럭터 : TensorFlow텐서의 "정수"를 발생
3. tf.Vatiable() 클래스의 컨스트럭터 : TensorFlow텐서의 "변수"를 발생
따라서 이전의 포스팅에서 설명에서는 def call(self, inputs, training): 이라는 코드로 training값을 받고 있다고 했다. 이 값은 model(tensor_input1, training=True)이라는 형태로, 추론 시에 지정할 수 있다. 훈련시에 순전파를 실행하는 경우는 training = True, 평가시에는 training=False를 지정하면 된다.
학습에 대해서
그럼 추론에 대한 설명은 이상으로, 지금부터는 학습에 대해서 이야기하겠다. 학습의 작성법에 대해서는 아래의 두 종류가 있다.
- 초중급자용 작성법 : compile() 과 fit()를 호출해, 간단하게 작성하는 방법
- 전문자용 작성법 : tf.GradientTape 클래스(자동 미분 기록 기능)을 사용한 유연하고 확장성이 높은 작성법 (PyTorch의 작성법에 가까운 방법)
옵티마이저(최적화용 오브젝트)
먼저 옵티마지어(최적화 알고리즘)부터이다.
# 【초중급자버전과 비교용】학습방법을 설정한다.
# model.compile(
# tf.keras.optimizers.SGD(learning_rate=0.03), # 최적화 알고리즘
# ……손실함수……,
# ……평가함수……)
# ###【전문가용】최적화 알고리즘을 설정한다. ###
optimizer = tf.keras.optimizers.SGD(learning_rate=0.03) # 갱신시의 학습률보았듯, 완전히 동일한 코드이다. 초중급자용과 전문가용의 차이점은 tf.keras.optimizers 이름공간(tf.optimizers이름 공간에도 액세스 가능)의 클래스(예:SGD)의 인스턴스를
- compile() 메소드의 인수에 지정할 것인가
- 변수에 대입할 것인가
일 뿐이다.
손실함수
다음은 손실함수이다.
# 【초중급자버전과 비교용】학습방법을 설정
# model.compile(
# ……최적화 알고리즘……,
# 'mean_squared_error', # 손실함수
# ……평가함수……)
# ###【전문가용】손실함수를 정의한다. ###
criterion = tf.keras.losses.MeanSquaredError()초중급자용과 전문자용의 차이점은
- 문자열(예 : 'mean_squared_error')로, compile() 메소드의 인수에 지정할 것인가
- tf.keras.losses 이름 공간(tf.losses 이름공간)의 클래스(예: MeanSquaredError)의 인스턴스를 변수에 대입할 것인가
이다.
또한, 변수명은 criterion로 했지만, 이것은 오차로부터의 손실을 측정 "기준(criterion)"를 의미한다. PyTorch에서는 criterion이 관례로, TensorFlow에서는 loss_object와 명명하는 경우가 많다.
평가함수
다음은 평가함수이다.
# 【초중급자버전과의 비교용】학습방법을 설정한다.
# model.compile(
# ……최적화 알고리즘……,
# ……손실함수……,
# [tanh_accuracy]) # 평가함수
# ### 【전문가용】평가함수를 정의한다. ###
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = TanhAccuracy(name='train_accuracy')
valid_loss = tf.keras.metrics.Mean(name='valid_loss')
valid_accuracy = TanhAccuracy(name='valid_accuracy')초중급자용과 전문가용의 차이점은
- tf.keras.metrics 이름공간(tf.metrics 이름공간) 의 변수명 (예: binary_accuracy, 이번에는 독자의 tanh_accuracy)를, compile() 메소드의 인수에 지정할 것인가
- tf.keras.metrics 이름공간(tf.metrics 이름공간)의 클래스 (예:Mean)의 인스턴스를 변수에 대입할 것인가
이다.
초중급자용의 compile()메소드는 자동적으로 손실(loss)를 계산해주고, 더욱이 훈련 데이터와 정밀도 검증 데이터는 나눠서 처리해준다. 그러므로, 정답률(accuracy)만을 평가함수로써 지정하면 된다.
한편, 전문가용의 경우는 내부에 은닉되어 있는 이러한 변수를, 수동으로 정의해줄 필요가 있다. tf.keras.metrics 이름공간을 베이스로써 클래스를 사용하고 있으나, 이로 인해 후술할 학습/평가에서 손실이나 정답률의 계산이 편해진다는 장점이 있다.
이상으로 complie()메소드에서 대응되는 부분이다. 다음은 fit() 메소드에 대응하는 부분을 살펴보자.
tf.data 데이터세트
# 【초중급자버전과의 비교】입력 데이터를 지정해서 학습한다.
# model.fit(
# X_train, y_train, # 훈련 데이터
# validation_data=(X_valid, y_valid), # 정밀도 검증 데이터
# batch_size=15, # 배치 데이터
# ……에포크……,
# ……실행 상태의 출력모드……)
# ###【전문가용】입력 데이터를 준비한다. ###
# NumPy다차원 배열의 데이터형을 데이터 세트(텐서)용으로 통일한다.
X_train_f32 = X_train.astype('float32') # np.float64형 → np.float32형
y_train_f32 = y_train.astype('float32') # 위와 동일
X_valid_f32 = X_valid.astype('float32') # 위와 동일
y_valid_f32 = y_valid.astype('float32') # 위와 동일
# 「입력 데이터(X)」와「훈련 라벨(y)」를 1개의「슬라이스 데이터 세트(TensorSliceDataset)」로 정리한다.
train_sliced = tf.data.Dataset.from_tensor_slices((X_train_f32, y_train_f32)) # 훈련용
valid_sliced = tf.data.Dataset.from_tensor_slices((X_valid_f32, y_valid_f32)) # 정밀도 검증용
# 셔플해서(훈련 데이터만), 미니 배치용의 「배치 데이터세트(BatchDataset)」로 한다.
train_dataset = train_sliced.shuffle(250).batch(15)
valid_dataset = valid_sliced.batch(15)
print(train_dataset)
# <BatchDataset shapes: ((None, 2), (None, 1)), types: (tf.float32, tf.float32)> ……등으로 표시된다.초중급자용과 전문가용의 차이는 데이터와 배치사이즈이다.
- fit() 메소드의 인수에 지정할 것인가
- tf.data 기능을 사용해 미니 매치용 데이터 세트를 작성하여, 변수에 대입할 것인가
이다.
tf.data는 TensorFlow 2.x 시대의 입력 데이터 관리 기능(입력 파이프 라인)으로, 전문자용으로 미니 배치 학습을 할 경우 유용한 툴이다. 그러나, 위에서 보았듯 코드가 길어진다.
코드의 의미는 주석으로 설명해뒀다. 포인트는 아래와 같다.
- 데이터형은 float32로 통일하면 다루기 쉽다 (astype(데이터형) 메소드 이용)
- tf.data.Dataset.from_tensor_slices()메소드로 NumPy 다차원배열 데이터를 tf.data의 세계로 가져올 수 있다.
- 훈련시에는 기본적으로 셔플이 필요하다. shuffle(버퍼 사이즈) 메소드의 버퍼 사이즈의 부분에는 (기본적으로) 모든 데이터건수 이상을 지정한다.
- 마지막으로 batch(배치 사이즈) 메소드를 호출하여, 훈련용/정밀도 검증용 데이터 세트를 생성하면 완료
학습 (1회분)
fit()메소드에서는 학습과 평가의 처리는 완전히 은닉되어 있어, 대응하는 코드 부분이 없어, 전문가용 코드만 작성되어 있다.
import tensorflow.keras.backend as K
# ###【전문자용】훈련한다.(1회분) ###
@tf.function
def train_step(train_X, train_y):
# 훈련모드로 설정
training = True
K.set_learning_phase(training) # tf.keras내부에도 전달할 수 있다.
with tf.GradientTape() as tape: # 기울기를 테이프에 기록
# 순전파 출력 결과를 취득
#train_X # 입력 데이터
pred_y = model(train_X, training=training) # 출력 결과
#train_y # 정답 라벨
# 출력 결과와 정답 라벨로부터 손실을 계산하고, 기울기를 구한다.
loss = criterion(pred_y, train_y) # 오차(출력 결과와 정답 라벨의 차)로 부터 손실을 취득
# 역전파의 처리로써 기울기를 계산(자동미분)
gradient = tape.gradient(loss, model.trainable_weights)
# 기울기를 사용하여 파라미터(가중치와 바이어스)를 갱신
optimizer.apply_gradients(zip(gradient, model.trainable_weights)) # 지정된 데이터분의 최적화를 실시
# 손실과 정답률을 계산하여 저장
train_loss(loss)
train_accuracy(train_y, pred_y)
# ###【전문가용】정밀도를 검증한다(1회분) ###
@tf.function
def valid_step(valid_X, valid_y):
# 평가모드를 설정(※dropout등의 동작이 평가용이 된다.)
training = False
K.set_learning_phase(training) # tf.keras내부에도 전달한다.
# 순전파 출력 결과를 취득
#valid_X # 입력 데이터
pred_y = model(valid_X, training=training) # 출력 결과
#valid_y # 정답 라벨
# 출력 결과와 정답 라벨로부터 손실을 계산
loss = criterion(pred_y, valid_y) # 오차(출력 오차와 정답 라벨의 차)로부터 손실을 취득
# ※평가시에는 기울기를 계산하지 않는다.
# 손실과 정답률을 계산하여 저장
valid_loss(loss)
valid_accuracy(valid_y, pred_y)위 코드를 살펴보면,
- 훈련(학습) 처리를 실행한 train_step 함수
- 정밀도 검증(평가) 처리를 구현한 valid_step함수
가 있다. 각각 미니 배치 학습의 1회분의 훈련, 정밀도 검증을 하고 있다.
기울기 테이프와 자동 미분
먼저 train_step 함수의 안을 살펴보자. pred_y = model(train_X)이라는 코드에서 추론이 실행되어, 예측값을 취득하고 있다. loss = criterion(pred_y, train_y)이라는 코드에서 그 예측값과 정답 라벨을 사용하여 손실 (loss)를 계산하고 있다. 이 2행의 코드는 with tf.GradientTape() as tape이라는 스코프 내에서 실행되고 있음을 주의하길 바란다.
tf.GradientTape클래스는 기울기 테이프(Gradient Tape)이라고 불리는TensorFlow 2.0의 신기능이다. "기울기"를 미분하는 것으로 얻어지는 값이다. '테이프"이란 카세트 테이트에 음악을 기록하는 것을 이미지하면 된다. 즉, 스코프 내에서 얻어진 손실을 사용하여 자동 미분할 때에 계산된 기울기가 기록되는 것이다.
자동미분(역전파)가 이뤄지는 곳이, gradient = tape.gradient(loss, model.trainable_weights)이라는 코드이다. tape는 방금의 기울기 테이프이다. tape.gradient() 메소드로 기울기를 계산하여, 변수 gradient에 대입하고 있다. 메소드의 인수에는 손실(loss)와 모델내의 훈련 가능한 가중치(model.trainable_weights)가 지정되어 있다.
가중치의 갱신
그러나, 이 단계에서는 먼저 기울기가 계산되는 것뿐으로, 모델 내의 가중치나 바이어스는 갱신되지 않는다. optimizer.apply_gradients(zip(gradient, model.trainable_weights)) 메소드를 호출하는 것으로 처음으로 갱신되는 구조로 되어 있다.
손실과 정답률
이상으로 1회본의 학습은 끝이다. 따라서 여기서는 1회분읜 손실과 정답률을 계산하여, 상태를 확인할 것 이다. 이것을
정밀도 검증 처리에 대해 확인하고자한다. 이것을 간단히 실행할 수 있는 것이, 평가함수 부분이다. 훈련용의 손실 평가 함수는 train_loss, 정답률의 평가 함수는 train_acuuracy이라는 함수에 정의해뒀다. 이것들을 함수와 같이 호출하고 있는 것이, train_loss(loss)와 train_accuracy(train_y, pred_y)이라는 2행의 코드이다. 이 코드만으로 손실과 정답률 계산, 저장된다.
정밀도 검증의 처리에 대해서
valid_step 함수의 쪽은 학습하는 것이 아니므로 기울기 계산(with.GradientTape() as tape와 tape.gradient())나 가중치의 갱신(optimizer.apply_gradients()) 불필요하다. 손실(loss)만을 계산하고, 그 결과를 평가함수인 valid_loss/valid_accuracy변수를 사용하여 보존하면 끝이다.
@tf.function과 AutoGraph
마지막으로, 각각의 함수 위에 @tf.function이라는 데코레이터가 부여되어 있는 것을 살펴보았음 한다. 이것은 필수는 아니지만, for등의 반복 처리에 있어서, 퍼포먼스가 좋아지는 효과가 있다. 실제로 위의 코드를 실행 시간을 측정하였을 때, @tf.function이 없는 경우는 20.3초정도, @tf.function을 붙인 경우 3.65초가 된다. 5.6배가 속도가 빨라지는 것이다.
@tf.function에 의한 퍼포먼스 향상은 케이스 바이 케이스이므로, 모든 경우에 적용된다고 할 수 없지만, 특히 train_step/valid_step함수에 지정하는 것을 추천한다. 그 외에서는 tf.keras.Model 파생 클래스 내의 call 메소드에 붙이는 것도 가능하다.
@tf.funtion은 TensorFlow 2.0에서 Eager 실행 모드가 디폴트가 되기 위해 도입된 기능이다. Eager 실행모드에서는 실행시에 동적으로 계산 그래프가 생성된다. 그러나 몇 번이고 동적으로 작성되면 당연히 실행 속도가 늦어져 버리게 된다. 여기서, 첫 번째 실행시에 계산 그래프를 구축하면, 두 번째는 그것을 정적인 계산 그래프와 같이 사용하면 보다 처리 속도가 빨라진다. @tf.fuction은 이러한 동작을 하기 위한 기능이다.
또한 @tf.funtion은 Python의 if문이나 for문/while문 등으로 작성된 코드를 계산 그래프용의 tf.cond()함수나 tf.while_loop() 함수등으로 자동적으로 바뀐다. 이 기능은 AutoGraph(자동 그래프)라고 불리고 있다.
그러나, 부작용도 있으므로, 어디서든 지정할 수 있는 것이 아니며, 지정 함수의 코드도 주의 깊이 작성할 필요가 있다.
학습(루프 처리)
드디어 막판에 이르렀다. 미니 배치 학습에서 배치마다 학습 & 평가하는 처리를 for루프를 사용하여 기재하면 된다. 먼저 데이터 전체에 상당하는 에포크마다의 for 루프를 만고, 그 안에 미니 배치마다의 fot 루프를 만드는 2단계의 구성을 만든다.
# 【초중급자버전과의 비교용】입력 데이터를 지정하여 학습한다.
# model.fit(
# ……훈련 데이터(입력)……, ……(라벨)……,
# ……정밀도 검증 데이터……,
# ……배치사이즈……,
# epochs=100, # 에포크 수
# verbose=1) # 실행 상태의 출력 모드
# ###【전문가용】학습한다. ###
# 정수(학습/평가시에 필요한 것)
EPOCHS = 100 # 에포크의 수: 100
# 손실 이력을 저장하기 위한 변수
train_history = []
valid_history = []
for epoch in range(EPOCHS):
# 에포크 마다, 매트릭스 값을 리셋
train_loss.reset_states() # 「훈련」시에 있어서 누계「손실치」
train_accuracy.reset_states() # 「훈련」시에 있어서 누계「정답률」
valid_loss.reset_states() # 「훈련」시에 있어서 누계「손실치」
valid_accuracy.reset_states() # 「훈련」시에 있어서 누계「정답률」
for train_X, train_y in train_dataset:
# 【중요】1 미니배치분의「훈련(학습)」을 실행
train_step(train_X, train_y)
for valid_X, valid_y in valid_dataset:
# 【중요】1 미니배치분의「평가(정밀도 검증)」을 실행
valid_step(valid_X, valid_y)
# 미니 배치 단위로 누계된 손실치나 정답률의 평균을 얻어낸다.
n = epoch + 1 # 처리가 끝난 에포크의 수
avg_loss = train_loss.result() # 훈련용의 평균 손실치
avg_acc = train_accuracy.result() # 훈련용의 평균 정답률
avg_val_loss = valid_loss.result() # 훈련용의 평균 손실치
avg_val_acc = valid_accuracy.result() # 훈련용의 평균 정답률
# 그래프를 그리기 위해 손실의 이력을 저장한다.
train_history.append(avg_loss)
valid_history.append(avg_val_loss)
# 손실이나 정답률 등의 정보를 표시한다.
print(f'[Epoch {n:3d}/{EPOCHS:3d}]' \
f' loss: {avg_loss:.5f}, acc: {avg_acc:.5f}' \
f' val_loss: {avg_val_loss:.5f}, val_acc: {avg_val_acc:.5f}')
print('Finished Training')
print(model.get_weights()) # 학습 후의 파라미터의 정보를 표시에포크마다의 루프는 for epoch in range(EPOCHS):이라는 코드로 미니 배치마다의 루프는 for train_X, train_y in train_dataset: / for valid_X, valid_y in valid_dataset이라는 코드에서 기재되어 있다. train_dataset/valid_dataset 변수는 이전 포스팅에서 언급한 데이터 세트이다.
미니 배치마다의 루프 내에, 아까 앞에서 구현한 train_step 함수나 valid_step함수가 호출되고 있음을 알 수 있다. 이 코드만으로 뉴럴 네트워크의 학습과 평가의 실행이 가능하다.
그 외의 코드는 손실이나 정답률과 같은 정밀도 검증/상태 표시를 위한 코드이다.
평가(매트릭스)
평가함수인 train_loss/train_accuracy/valid_loss/valid_accuracy에는 공통되는 아래와 같은 메소드가 있다(엄밀히 말하자면 tf.keras.metrics.Metric 클래스의 메소드).
- reset_state() 메소드 : 손실이나 정답률과 같은 매트릭스(측정값)을 리셋
- result()메소드 : 매트릭스(측정값)의 획득
이러한 것을 사용하여, 에포크마다 먼저 매트릭스 값을 초기화하고, 모든 배치를 처리 한 후에 매트릭스 값을 취득하고, 그 내용을 print()함수로 출력한 결과는 아래와 같다.

평가 (추이 그래프)
또한, 매트릭스 마다, 손실값을 각 에포크이력으로써 train_history/valid_history변수에 저장하고 있다. 저장하는 것으로 다음의 코드를 이용해 그래프를 그리는 것이 가능하다.
import matplotlib.pyplot as plt
# 학습 결괴(손실)의 그래프를 그린다.
epochs = len(train_history)
plt.plot(range(epochs), train_history, marker='.', label='loss (Training data)')
plt.plot(range(epochs), valid_history, marker='.', label='loss (Validation data)')
plt.legend(loc='best')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()위 코드를 실행시키면 다음과 같이 손실 추이 그래프를 확인할 수 있다.

참고자료
https://atmarkit.itmedia.co.jp/ait/articles/2003/10/news016.html
'IT > AI\ML' 카테고리의 다른 글
| [python] 결정계수 R2와 자유도 조정 결정 계수 R*2 (0) | 2021.11.28 |
|---|---|
| [Tensorflow] Tensorflow Profiler 사용법 (0) | 2021.09.21 |
| [python/tensorflow2.x] Tensorflow2.x버전 작성법(1) (0) | 2021.09.11 |
| [python] 데이터 사이언티스트(데이터 분석가)에 도움이 되는 Tip : yield, partial, map, filter, reduce, enumerate (0) | 2021.08.03 |
| [python/Tensorflow] TFRecord를 만들어서 최소한의 CIFAR-10데이터로 학습시키기 (0) | 2021.07.30 |