1. RNN(Recurrent Neural Network)란?
음악, 동영상, 에세이, 시, 소스 코드, 추가 차트의 공통점은 바로 시퀀스라는 점이다. 여기서 시퀀스(sequence)란 연관된 연속의 데이터를 의미한다. 음악은 음계들의 시퀀스, 동영상은 이미지의 시퀀스, 에세이는 단어들의 시퀀스 등으로 볼 수 있다. 한 페이지의 에세이, 한 권의 에세이 등이 있듯 시퀀스의 길이는 가변적이다. 기존의 뉴럴 네트워크 알고리즘은 고정된 크기의 입력을 다루는 데는 탁월하지만, 이러한 가변적인 크기의 데이터를 모델링하기에는 적합하지 않 는 문제점이 있었다.
이 때 등장한 것이 바로 RNN(Recurrent Neural Network, 순환신경망)이다. RNN이 기존 뉴럴 네트워크와 다른 점은 '기억'(다른 말로 hidden state)을 갖고 있다는 점이다. 네트워크의 기억은 지금까지의 입력 데이터를 요약한 정보라고 할 수 있다. 새로운 입력이 들어 올 때 마다 네트워크는 지금 들어 온 입력 데이터와 과거에 입력 받았던 데이터를 동시에 고려하여 기억을 조금씩 수정한다. 결국 입력을 모두 처리하고 난 이후 네트워크에게 남겨진 기억은 시퀀스 전체를 요약하는 정보가 된다. 이는 사람이 시퀀스를 처리하는 방식과 비슷하다. 이러한 과정은 새로운 단어마다 계속해서 반복하기 때문에 Recurrent, 즉 '순환적'이라는 이름이 붙었다.
2. Vanilla RNN (Recurrent Neural Network)

가장 단순한 형태의 RNN은 모델은 위와 같다. t는 sequence data의 특정 시점의 데이터를 의미한다. 앞서 말했듯 RNN은 지금 들어 온 입력 데이터와 과거에 입력 받았던 데이터를 동시에 고려하기 때문에 t-1시점(이전 시점)의 RNN출력값은 t시점(현 시점)의 RNN의 출력값에 영향을 준다고도 표현할 수 있다.
그러한 구조를 수식으로 표현하자면 아래와 같다. 위 사진의 수식과 형태가 달라보이지만 자세히 보면 위 사진의 두 번째 수식과 동일함을 알 수 잇다.

시간 t에서 은닉층의 상태, 즉 은닉층이 갖고 있는 값을 h_t라고 하겠다. 이 값은 같은 시점 t에 들어온 입력 x_t와 계수 행렬 W, 시간 t-1에서 은닉층의 값 h_t-1, 그리고 h_t와 h_t-1의 관계를 나타내는 행렬 U의 함수이다. (이 행렬 U는 Markov 체인의 상태 전이 행렬(transition matrix)과 비슷하다.) 계수 W는 지금 들어온 입력과 보유하고 있던 기억(은닉층의 값)이 얼마나 중요한지 판단하는 값이다. 예를 들어 W가 아주 큰 값으로 이루어져 있다면 기억하고 있는 h는 별로 중요하지 않고, 현재 들어온 입력값 x_t를 위주로 판단을 내린다. 이전의 네트워트와 마찬가지로 출력단에서 오차를 계산하고 이 오차는 다시 이 은닉층으로 내려오는데, 그 값을 기준으로 W업데이트한다.
입력 x와 기억 h의 합은 함수 φ를 통과하면서 압축된다. 보통 함수로 tanh나 로지스틱 시그모이드(logistic sigmoid)를 사용한다. tanh나 로지스틱 시그모이드(logistic sigmoid) 함수는 출력값의 범위를 제한해주면서 전 구간에서 미분 가능하기 때문에 backprop이 잘 적용되기 때문이다.
여기에서 h_t와 h_t-1의 피드백(; 과거의 출력이 다시 입력이 되는)은 매순간마다, 즉 모든 t마다 이루어진다. 그런데 h_t의 값을 구하기 위해선 h_t-1이 필요하고, h_t-1의 값을 구하는데는 다시 h_t-2가 필요하다. 결과적으로 은닉층은 과거의 h를 전부 기억하고 있어야 하는데, 실제로 값을 무한히 저장할 수는 없으므로 사용 가능한 메모리 등 여러 상황에 맞추어 적당한 범위까지만 저장한다.
예를 들어 RNNs이 문자열을 입력받으면, 우선 첫 번째 문자로 학습을 하고 학습한 내용을 은닉층에 저장한다. 그리고 이 값을 이용해 두 번째 입력을 처리한다. 예를 들면 q 다음엔 u가 올 확률이 높고, t다음엔 h가 올 확률이 높은데, 이 정보를 이용할 수 있다.
RNNs을 애니메이션으로 시각화하면 더 쉽게 이해할 수 있을 것이다.

애니메이션에서 x는 입력, w는 입력 데이터에 곱해지는 가중치, a는 은닉층의 활성값(=입력과 은닉층 값을 고려해서 구해지는 값), b는 은닉층이 sigmoid 함수를 통과한 출력이다.
3. RNN 구현
tf.keras를 이용하여 코드로 구현해보자. 본격적으로 구현하기에 앞서 tf.keras의 API를 이용해 두 가지 방법으로 구현할 수 있다는 점을 밝힌다.
# ( 방법 1 )
# RNN, LSTM, GRU 등 특정 셀을 선언하고 이를 루프하는 코드를 따로 작성하여 활용하는 방법이다.
cell = layers.SimpleRNNCell(units=hidden_size) # hidden_size 는 output , 즉 출력의 크기를 설정
rnn = layers.RNN(cell, return_sequences= True, return_state = True)
outputs, states = rnn(x_data) # x_data는 Xt, 즉 input 데이터의 값
# 결국 outputs에는 나온 ht값이 states는 옆으로 이동해서 영향을 줄 states의 값이 저장된다.# ( 방법 2 )
# RNN, LSTM, GRU 등 특정 셀을 선언하고 이를 루프하는 코드를 같이 작성할 수 있는 API를 활용하는 방법이다.
rnn = layers.SimpleRNN(units=hidden_size, return_sequences=True, return_state = True)
outputs, states = rnn(x_data)첫 번째 방법의 장점은 LSTM, GRU 등 다른 셀로 작성하여 테스트해 볼 수 있다는 점이다.
1) 시퀀스가 1인 경우의 RNN 구현
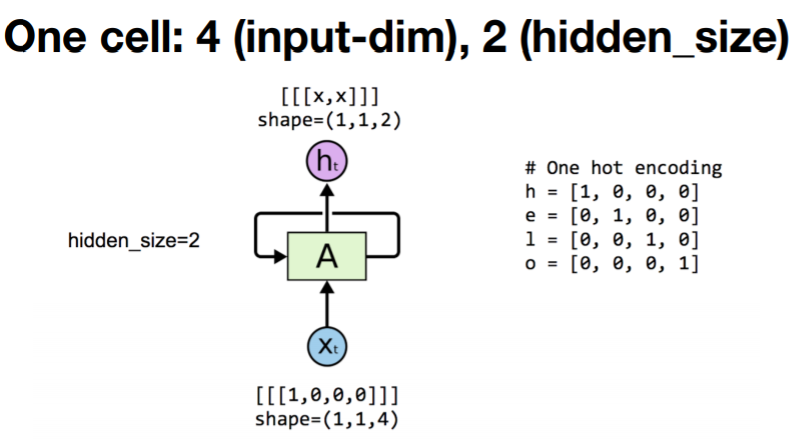
현재 위 그림은 h에 해당하는 one hot vector를 RNN이 처리하는 과정을 표현한 것이다. 주목해야할 것은 Input의 shape가 (1,1,4)로 표현되어 있다는 것인데, 이는 tensorflow에서 RNN이 입력으로 전달받는 데이터는 (batch_size, sequence_length, input_dimension)으로 표현되도록 전처리되어야 함을 의미한다. 또한 hidden_size를 2로 설정하였으므로, output의 데이터 shpape가 (1,1,2)로 변경된 것을 확인할 수 있다. 이 내용을 바탕으로 구현한 코드는 다음과 같다.
(1) laibraries import
# setup
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import Sequential, Model
print(tf.__version__)2.1.0
(2) Preparing dataset
# One hot encoding for each char in 'hello'
h = [1, 0, 0, 0]
e = [0, 1, 0, 0]
l = [0, 0, 1, 0]
o = [0, 0, 0, 1]x_data: [[[1. 0. 0. 0.]]], shape: (1, 1, 4)
outputs: [[[-0.06496636 0.16384147]]], shape: (1, 1, 2)
states: [[-0.06496636 0.16384147]], shape: (1, 2)
# One cell RNN input_dim (4) -> output_dim (2) > RNN을 활용하기 위한 전처리
x_data = np.array([[h]], dtype=np.float32)
hidden_size = 2
cell = layers.SimpleRNNCell(units=hidden_size) # creating SimpleRNNCell
rnn = layers.RNN(cell, return_sequences=True, return_state=True) # analogous to tf.nn.dynamic_rnn
outputs, states = rnn(x_data)
# RNN이 처리한 결과를 프린팅
print('x_data: {}, shape: {}'.format(x_data, x_data.shape))
print('outputs: {}, shape: {}'.format(outputs, outputs.shape))
print('states: {}, shape: {}'.format(states, states.shape))x_data: [[[1. 0. 0. 0.]]], shape: (1, 1, 4)
outputs: [[[0.29165375 0.30209106]]], shape: (1, 1, 2)
states: [[0.29165375 0.30209106]], shape: (1, 2)
outputs와 states의 값은 같지만 shape가 다른 것을 확인할 수 있다.
둘의 shape가 차이가 나는 이유는 ouputs 변수는 전체 시퀀스에 해당하는 hidden states 값들을 가지고 있고, states변수는 시퀀스의 마지막 hidden states값만 가지고 있기 때문이다.
이 예제에서는 알파벳 h하나만 RNN에 입력으로 전달하였으므로, 이 데이터는 시퀀스가 1이므로 다음과 같은 결과가 나오는 것이다.
# equivalent to above case
rnn = layers.SimpleRNN(units=hidden_size, return_sequences=True,
return_state=True) # layers.SimpleRNNCell + layers.RNN
outputs, states = rnn(x_data)
print('x_data: {}, shape: {}'.format(x_data, x_data.shape))
print('outputs: {}, shape: {}'.format(outputs, outputs.shape))
print('states: {}, shape: {}'.format(states, states.shape))x_data: [[[1. 0. 0. 0.]]], shape: (1, 1, 4)
outputs: [[[-0.7117611 -0.28176913]]], shape: (1, 1, 2)
states: [[-0.7117611 -0.28176913]], shape: (1, 2)
2) 시퀀스가 4인 RNN 구현
이번에는 시퀀스가 1이 아닌 데이터를 처리해보도록 하겠다.
즉, 앞에서는 h만 입력값으로 넣었다면 여기서는 h,e,l,o값을 모두 넣어서 RNN으로 처리해보겠다.
라이브러리 임포트와 데이터 셋 준비코드는 앞과 동일하다.

# One cell RNN input_dim (4) -> output_dim (2). sequence: 5
# 각각의 알파벳에 해당하는 one hot vector를 기반으로 시퀀스로 만들고 RNN이 처리할 수 있도록 전처리 작업
x_data = np.array([[h, e, l, l, o]], dtype=np.float32)
hidden_size = 2
rnn = layers.SimpleRNN(units=2, return_sequences=True, return_state=True)
outputs, states = rnn(x_data)
print('x_data: {}, shape: {} \n'.format(x_data, x_data.shape))
print('outputs: {}, shape: {} \n'.format(outputs, outputs.shape))
print('states: {}, shape: {}'.format(states, states.shape))x_data: [[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]], shape: (1, 5, 4)
outputs: [[[0.47337022 0.3929786 ]
[0.39179134 0.8714687 ]
[0.20688158 0.670787 ]
[0.08288943 0.5157672 ]
[0.16079137 0.22633114]]], shape: (1, 5, 2)
states: [[0.16079137 0.22633114]], shape: (1, 2)
ouputs 변수는 전체 시퀀스에 해당하는 hidden states 값들을 가지고 있고, states변수는 시퀀스의 마지막 hidden states값을 가지고 있기 때문에 outputs 변수의 마지막 hidden states와 동일한 값을 가지고 있음을 확인할 수 있다.
3) Batching input
이번에는 시퀀스가 5인 데이터 3개로 구성된 mini_batch를 RNN으로 처리해보도록 하겠다.
참고로 서로 다른 시퀀스의 길이를 가진 데이터로 구성된 mini_batch 또한 padding, masking과 같은 테크닉을 통해서 RNN으로 처리할 수 있다. 이에 대한 내용은 다음에 다루도록 하겠다.

# One cell RNN input_dim (4) -> output_dim (2). sequence: 5, batch 3
# 3 batches 'hello', 'eolll', 'lleel'
x_data = np.array([[h, e, l, l, o],
[e, o, l, l, l],
[l, l, e, e, l]], dtype=np.float32)
hidden_size = 2
rnn = layers.SimpleRNN(units=2, return_sequences=True, return_state=True)
outputs, states = rnn(x_data)
print('x_data: {}, shape: {} \n'.format(x_data, x_data.shape))
print('outputs: {}, shape: {} \n'.format(outputs, outputs.shape))
print('states: {}, shape: {}'.format(states, states.shape))x_data: [[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
[[0. 1. 0. 0.]
[0. 0. 0. 1.]
[0. 0. 1. 0.]
[0. 0. 1. 0.]
[0. 0. 1. 0.]]
[[0. 0. 1. 0.]
[0. 0. 1. 0.]
[0. 1. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]]], shape: (3, 5, 4)
outputs: [[[-0.645808 0.72146475]
[-0.72302413 0.39660427]
[-0.6221616 -0.04099922]
[-0.37129605 0.24864785]
[ 0.31115216 0.09358862]]
[[ 0.03242071 0.55417895]
[ 0.437557 -0.37179688]
[ 0.57976246 -0.10018117]
[ 0.5495411 -0.38326326]
[ 0.6407725 -0.1557154 ]]
[[ 0.0893703 -0.14354324]
[ 0.24137822 -0.0806519 ]
[ 0.26843232 0.49897614]
[-0.04325086 0.06279302]
[ 0.01772678 -0.16835481]]], shape: (3, 5, 2)
states: [[ 0.31115216 0.09358862]
[ 0.6407725 -0.1557154 ]
[ 0.01772678 -0.16835481]], shape: (3, 2)
outputs 변수는 mini_batch를 구성하고 있는 각각의 데이터의 전체 시퀀스에 해당하는 hidden states를 가지고 있다.
states 변수는 mini_batch를 구성하고 있는 각각의 데이터 시퀀스에 마지막 hidden states값을 가지고 있다.
4. 다양한 RNN의 형태
RNN의 형태는 우리가 네트워크에게 시키고 싶은 것이 무엇이냐에 따라 얼마든지 달라질 수 있다. 아래의 그림은 다양한 RNN 구성의 예시이다.

one to many의 경우 특정 이미지를 입력으로 받아 캡션을 생성하는 이미지 캡션 분야에 활용할 수 있으며,
many to many의 경우 문장을 입력받아 문장으로 출력되는 neural machine translation 분야나 문장을 입력받아 문장의 형태소를 분석해주는 형태소 분석기 등에 활용될 수 있다.
참고자료
https://www.edwith.org/boostcourse-dl-tensorflow/lecture/43750/
https://pathmind.com/kr/wiki/lstm
https://dreamgonfly.github.io/rnn/2017/09/04/understanding-rnn.html