※ 일본의 한 블로그 글을 번역한 포스트입니다. 오역 및 의역, 직역이 있을 수 있으며 틀린 내용은 지적해주시면 감사하겠습니다.
이번에 설명할 구현 클래스
자주 사용되는 Collection계 클래스는 다음과 같다.
- ArrayList
- LinkedList
- HashSet
- HashMap
HashMap은 Collection이 아닌 Map의 구현 클래스이지만, 자주 사용되는 점과 HashSet과 관계가 깊기 때문에 이번에 함께 설명하도록 하겠다.
클래스 그림은 다음과 같다.
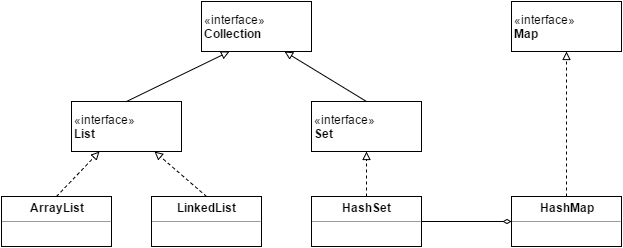
그리고, 인터페이스의 역할은 다음과 같다.
| 인터페이스 | 역할 |
| List | 요소의 순서가 부여된 그룹. 기본적으로 중복이 허가된다. |
| Set | 요소의 중복을 허가하지 않은 그룹(집합). 순서는 구현 클래스에 따른다. |
ArrayList ; 배열에 의한 List
ArrayList는 그 이름 그대로 배열(Array)의 List이다. 내부에서 배열을 가지므로 배열에 대해서 데이터의 저장이나 참조, 삽입 등을 할 수 있다. 그러므로 ArrayList의 특징을 알기 위해서는 배열의 특징도 알아야할 필요가 있다.
그렇다면 배열이란?
배열은 메모리상에 연속된 영역을 확보한 것이다. 가장 큰 특징은 첨자를 참조해 속도가 빠르다는 점이다.
영역이 연속되어 있으므로, 맨 앞의 주소, 첨자, 데이터 1개당 사이즈를 알면 참조하고 싶은 어드레스를 아래의 식으로 구할 수 있다.
| 참조할 어드레스 = 맨 앞의 주소 + 첨자 x 데이터 1개당 사이즈 |
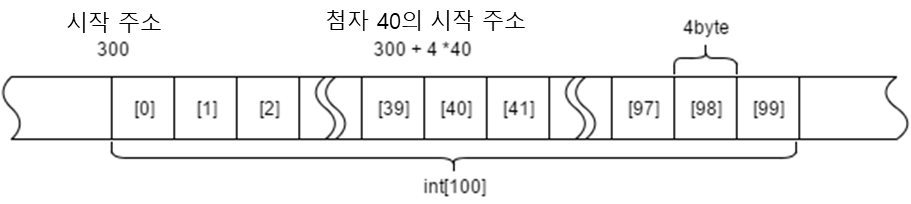
ArrayList의 내부처리
배열은 이와 같이 연속된 영역을 확보할 필요가 있기 때문에, 원래라면 맨 처음에 결정된 요소의 개수를 변경하는 것은 할 수 없다.
그러나 ArrayList에서는 동적으로 요소를 추가할 수 있다. ArrayList에서는 요소를 추가함으로써 배열이 부족해진 경우 자동적으로 배열을 재확보한다.
재확보라는 것은 실제로는 원래 사이즈보다 1.5배 요소수를 가진 배열을 new하여, 원래 배열에서 데이터를 복사하는 처리를 실행하므로 매우 무거운 처리를 하게 된다.
ArrayList에서는 초기의 용량(컨스트럭트 인수)를 결정하는 쪽이 좋다고 말하는 이유는 맨 처음에 확보한 배열의 크기를 결정해두면 재확보 처리가 실행되는 빈도가 줄기 대문이다.
또한, 배열은 삽입에 매우 약하다. 데이터가 저장된 영역이 고정되어 있으므로 장소를 바꾼다는 처리는 되지 않기 때문이다.
ArrayList에서는 add메소드로 임의의 장소에 데이터를 삽입 처리를 구현하고 있지만, 이 또한 내부적으로 배열의 재확보를 하기 때문에, 삽입 위치보다 뒤의 데이터는 인덱스를 한칸씩 이동하여 복사하는 것으로 삽입한다.
LinkedList ; 선형 리스트에 의한 List
선형 리스트이라는 데이터 구조를 들어본 적이 있는가? LinkedList는 선형 리스트의 구조를 바탕으로 한 List이다.
선형 리스트란?
선형 리스트는 데이터와 링크(다음 요소로의 참고)를 1개의 오브젝트(노드)로써 다뤄, 로드를 연결해나가는 것으로 데이터열을 다루는 데이터 구조를 일컫는다.
이 데이터 구조의 이점은 루트(맨 처음의 노드로의 참조)를 알고 있다면 각 노드내의 링크를 따라가면서 요소에 접근할 수 있다는 점이다. 그러므로 배열에 존재하는 각 노드가 연속된 영역으로 존재할 필요가 없다.
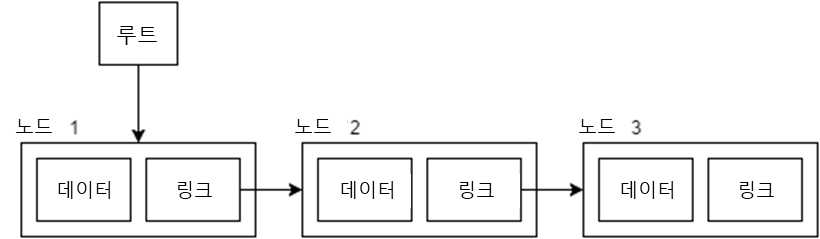
LinkedList의 내부처리
선형 리스트의 단점은 랜덤 액세스가 느리다는 점이다. 예를 들어, 두 번째 요소에 액세스하기 위해서는 [루트] > [0번째 요소] > [1번째 요소] > [2번째 요소]이라는 루트에서 링크를 따라 조작할 필요가 있기 때문이다.
LinkedList에서는 조금이라도 랜덤 액세스를 고속화하기 위해 링크를 양방향으로 하거나, 맨 뒤의 요송로의 참조를 유지하는 등의 방법을 사용하고 있다.
그러나, 요소가 많으면 많을 수록 랜덤 액세스가 늦어지는 케이스가 발생할 수 있다. 또한, 각 노드가 데이터 이외에 참조를 필드로써 가지는 것으로 동일 요소수의 ArrayList보다도 메모리 사용량이 많아지게 된다.
HashSet ; 해쉬값을 이용한 Set
HashSet은 방법 두 개의 List와 달리 Set의 구현 클래스이다. 따라서 요소의 중복을 허하지 않고, 랜덤 액세스를 할 수 없다.
또한 HashSet에서는 순서를 유지하지 않는다. 중복을 허가하지 않는다는 것은 요소를 추가할 때에 미리 그 요소가 Set내에 존재하는지 아닌지를 판정할 필요가 있다는 것이다.
HashSet에서는 배열, 선형 리스트, 해시값을 적절히 잘 사용하는 것으로 빠른 속도로 존재 확인을 구현하고 있다.
해시값이란
해시값은 원래의 데이터에서 특정 식을 바탕으로 계산하여 산출된 값이다. 동일 데이터에서는 동일한 해시값이 계산되지만, 조금이라도 데이터가 다른 경우는 값이 크게 달라지도록 설계되어 있다. 해시값 자체는 인증이나 정당성 체크, 암호화등 정보 처리의 세계에서 폭넓게 사용되고 있다.
Java에 있어서의 해시값
Java에 있어서의 해시값은 인스턴스를 식별하기 위한 값으로 hashCode메소드로 산출된 int형 정수이다. hashCode메소드는 Object형으로 정의되어 있다.
“같은 데이터에서 동일 해시값이 계산할 수 있다”는 특징을 바탕으로, equals 메소드가 true를 반환하는 인스턴스간에서는 동일 해시값을 반환해야하며, 반대로 데이터가 다른 경우에는 되도록 동일한 값이 되지 않도록 할 필요가 있다.
HashSet의 내부처리
HashSet은 이 해시값을 적절히 잘 사용하는 것으로 빠르게 그 값이 존재하는지를 확인하는 로직을 구현하고 있다.
HashSet은 인스턴스화된 단계에서 사이즈 s의 배열을 확보한다. 어떤 인스턴스 e를 저장할 때 HashSet은 먼저e.hashCode()로 해시값을 구하고 그 값에서 부터 저장되어 있을 만한 장소를 산출한다.
array[ e.hashCode() % s ] = e;e.hashCode()와 s의 나머지값(나눗셈후의 여분)을 구해, 그 장소에 e를 저장한다. 저장장소는 e.hashCode() % s로 부터 산출되므로, 존재 확인을 하는 경우에 배열 내를 하나 하나 조사하여 검색할 필요가 없고, 부여된 인스턴의 해시값을 계산하여 거기에 인스턴스가 있는지 없는지를 확인하는 것으로 존재 여부 확인을 하는 것이다.
충돌하는 경우
이것은 어디까지나 이상론이다. 실제로는 배열 사이즈 s는 해시값과 비교해 작은 수이므로 저장하려고 한 장소에 이미 데이터가 있다라는 현상이 발생한다. 이것을 충돌이라고 부른다.
충돌이 발생한 경우 HashSet에서는 데이터 저정시에 선형 리스트와 같이 다음 요소로의 링크를 가진 데이터 구조로 데이터를 저장한다.
그리고 충돌이 발생한 경우에는 이미 존재하는 요소의 다음 요소로서 데이터를 연결해나간다.이것으로 한번도 참조하지 않고도 e.hashCode() % s의 값이 같아지는 그룹만을 검색해 나가는 것으로 존재여부를 확인할 수 있다.

리사이즈
데이터가 늘면 늘수록 충돌 가능성도 높아진다. 예를 들어 s=10의 경우에 11개의 데이터를 저장하려고 하면, 확실히 충돌이 발생하게 된다.
여기서 데이터수가 늘어난 경우에 배열을 큰 용량으로 재확보하여, 데이터를 다시 넣는 처리를 실행한다.여기에서 데이터의 다시 넣는다는 것은 단순히 복사가 아닌 배열의 첨자와 e.hashCode()%s의 대응이 붕괴되지 않도록 하므로 구조가 붕괴되는 것은 아니다.
hashCode의 오버라이드
HashSet은 hashCode의 값에 따라 저장 장소를 판단한다. 그러므로, hashCode의 식의 성능이 HashSet의 충돌확률에 직결된다. 극단적 이야기로 hashCode의 안을 return 0;으로 하여 항상 정수를 반환하도록 처리하면 데이터 저장시마다 충돌이 발생하므로, 검색 성능이 LinkedList보다 떨어진다.
그러므로 저장된 요소의 클래스에 적절한 hashCode메소드를 오버라이드하는 것이 중요하다. 그렇다고 해도 hashCode에서는 충돌 가능성이 높다. 가장 좋은 것은 Objects.hashCode메소드를 사용하는 것이다.
Objects.hashCode(필드1, 필드2, 필드3);인수가 가변 인수이므로, 여러 개의 Object형의 데이터를 전달하는 것이 가능하다. 그러나 각 필드의 hashCode에서 구해진 해시값을 사용하여 마지막 해시값을 산출하므로, 각각의 필드의 클래스라도 hashCode 메소드를 오버라이드할 필요가 있다.
HashSet과 HashMap
여기까지 HashSet의 내부 구현 이야기를 했지만, 사실 거짓이다. 실제는 HashSet의 내부 구현이라는 것은 HashMap으로 구현되어 있다.
그러므로 지금까지 이야기한 내부 구현의 이야기는 실제로는 HashMap의 내부 구현이라는 것이다. 그러나 내부처리의 구현을 HashMap에 의존하고 있을뿐이므로 동작 자체는 큰 차이가 없다.
HashMap이야기
HashMap에 대해서 만져보면 HashMap은 Map의 구현 클래스로, Key와 Value이라는 두 개의 데이터 페어값을 가지고 있고 있다는 것을 알 수 있다.
Key는 방금까지 설명해 온 HashSet의 데이터의 부분에 해당하는 것이다. Key인스턴스의 해시값으로 데이터 저장을 하므로 Key를 바탕으로 데이터를 고속 검색하는 것이 가능하다.
Value는 단순히 Key에 연결된 값으로, Key와 함께 저장되어 있다. HashSet에서는 Value로써 static값을 설정하여 불필요한 메모리 소비를 방지하고, HashMap을 사용하여 구현한다.
각 클래스의 비교
정리로 각 구현 클래스의 성능을 비교해보자. 참고로 O(1)보다도 O(n)쪽이 느리다.
| 구현 클래스 | 추가 | 삽입/삭제 | 검색 | 랜덤 액세스 | 메모리 사용량 |
| ArrayList | O(1)※ | O(1) | O(n) | O(1) | 적음 |
| LinkedList | O(1) | O(1) | O(n) | O(n) | 중간 |
| HashSet | O(1)※ | O(1) | O(1) | 불가능 | 많음 |
※ 리사이즈 발생 가능성이 있는 것
비교해보면 각 구현 클래스의 특징이 보인다. 예를 들어, 삽입이 많으면 LinkedList, 랜덤 액세스가 많으면 ArrayList과 같은 따른 처리 내용에 따라 어떤 클래스가 좋은지를 알 수 있다.
'IT > 언어' 카테고리의 다른 글
| [Vue.js] slot에 대해 이해하기 (0) | 2023.04.18 |
|---|---|
| [Vue.js] Vuex를 가볍게 배워보자 (0) | 2023.04.13 |
| [Java] Stream의 map과 flatMap의 차이점 (0) | 2023.04.08 |
| [Java] Stream API의 anyMatch(), allMatch(), noneMatch() (0) | 2023.04.06 |
| [Vue.js] v-if와 v-show의 차이 (0) | 2023.03.31 |