|
<목차> 1. scikit-learn이란 2. scikit-learn을 이용하기 위해서 3. scikit-learn의 주요 기능 4. scikit-learn의 사용 방법 5. scikit-learn을 사용한 기계학습(1) 6. scikit-learn을 사용한 기계학습(2) 7. scikit-learn에 대해 더 자세하게 배우고 싶다면 |
1. scikit-learn이란
scikit-learn이란 python을 대표하는 머신러닝 라이브러리이다. '사이킷런'이라고 부르기도 한다. scikit-learn은 오픈 소스로 공개되어 있으며, 개인, 비즈니스 관계없이 누구나 무료로 사용가능하다. scikit-learn은 현재도 활용하여 개발이 이루어지고 있으며, 인터넷 상에서 정보를 찾기에도 싶다. 많은 머신러닝 알고리즘이 구현되어 있는데, 어떤 알고리즘도 같은 방식으로 이용이 가능하다. 또, 샘플 데이터 셋(토이 데이터 셋)이 부속되어 있으므로, 설치하여 바로 기계 학습을 시험해볼 수 있다. 그러므로 초심자가 기계학습을 배우기 시작할 때 적합한 라이브러리라고 말한다.
2. scikit-learn을 이용하기 위해서
scikit-learn는 아나콘다 등과 같은 개발환경 패키지에서 간단하게 이용 가능하다. 아나콘다는 데이터 분석이나 그래프 그리기 등, 파이썬에 자주 사용되는 라이브러리를 포함한 개발환경이다. 아나콘다를 설치하는 것만으로도 scikit-learn을 금방 이용하는 것이 가능하다.
아나콘다에 scikit-learn이 설치되어 있는지는 메뉴 화면의 Environments에서 Installed을 선택해, 검색창에 「scikit-learn」을 입력하면 확인할 수 있다.
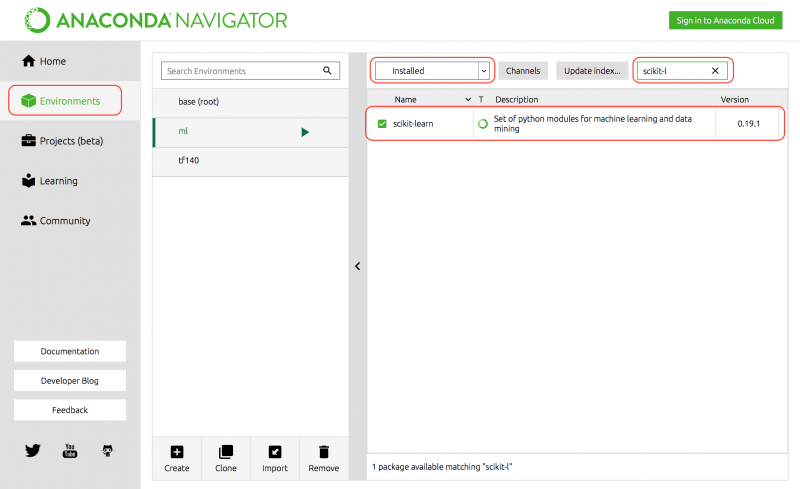
추가로, 아나콘다 등의 개발 환경을 이용하지 않고 수동으로 scikit-learn을 설치해 사용할 수도 있다. 다만 scikit-learn을 설치하기 전에는 사전에 이하의 라이브러리에 대한 설치가 필요하다.
- Numpy
- Scipy
- Pandas
3. scikit-learn의 주요 기능
다음은 scikit-learn의 주요한 기능, 특히 기계학습 모델에 대해 설명한다. 아래의 이미지는 scikit-learn의 알고리즘 치트 시트로 불린다. scikit-learn을 이용하여 기계학습을 실행할 때, 자신이 하고 싶은 분석(분류/회귀/클러스터링 등)에 대해서 적당한 모델을 선택하는 것에 대해 도움이 된다. 그리고 scikit-learn으로 간단히 모델을 바꿔 기계학습을 하는 것도 가능하다. 모델 변환에 대해서는 아래의 항목에서 설명하겠다.

1) 분류(classification)
주어진 데이터가 어느 클래스에 속하는 판별하는 것이다.
선생이 있는 학습의 분류 문제를 푸는 알고리즘이라고 표현할 수 있다.
다음과 같은 종류가 있다.
(1) SGD(stochastic gradient descent)
대규모 데이터(10만건 이상)의 경우 추천한다. 선형의 클래스 분류 방법이다.
(2) 커넬근사
SGD로 잘 분류할 수 없는 경우에 이용하며, 비선형적인 클래스 분류방법이다. 이것도 대규모 데이터에 적합하다.
(3) Linear SVC
중소규모(10만건 미만)의 경우 추천하며, 선형의 클래스 분류 방법이다.
(4) k근접법
Linear SVC로 잘 분류되지 않는 경우 사용하며, 비선형적인 클래스 분류 방법이다. 이것은 중소 규모의 데이터 분류에 추천한다.
2) 회귀(regression)
전달된 데이터를 바탕으로 값을 예상한다.
선생이 있는 학습 회귀 문제를 해결하는 알고리즘이라고 표현이 가능하다.
아래와 같은 종류들이 있다.
(1) SGD(stochastic gradient descent)
대규모 데이터(10만건 이상)의 경우 추천하는 선형 회귀 분석 방법이다.
(2) LASSO、ElasticNet
중소규모(10만건 미만)으로 *설명 변수의 일부가 중요한 경우에 추천하는 회귀 분석 방법이다.
(*설명 변수란 ? 어떤 원인이 되고 있는 변수이다.)
(3) Ridge、Liner SVR
중소규모(10만건 미만)으로 설명 변수의 전부가 중요한 경우에 추천하는 회귀 분석 방법이다.
(4) SVR(가우스 커넬)、Ensemble
Ridge또는 Liner SVR로 잘 분석되지 않는 경우 이용하며, 비선형적 회귀 분석 방법이다.
3)클러스터링(clustering)
전달된 데이터를 어떤 규칙에 따라 나누는 것이다.
선생이 없는 학습 클러스터링 문제를 해결하는 알고리즘이라고 표현할 수 있다.
아래와 같은 종류들이 있다.
(1) KMeans
몇 개의 클러스터를 분할할지, 사전에 정해둔 경우 추천하는 클러스터링분석방법이다.
대규모 데이터의 경우, MiniBatch라고 해서 데이터를 나누면서 학습시키는 방법을 취한다.
(2) 스펙트럼 클러스터링(GMM)
KMeans로 잘 분석되지 않는 경우에 이용하며, 비선형적인 클러스터링 분석 방법이다.
(3) MeanShift、VBGMM
몇 개의 클러스터로 나눌지에 대해, 사전에 정할 수 없는 경우에 추천하는 클러스터링 분석 방법이다.
4) 그 외 기타 기능
(1) 차원감소
전달된 데이터의 차원 수가 많은 경우, 학습효율이 떨어지므로 차원을 감소시키는 전처리를 실시한다.
PCA、커넬PCA、Isomap、SpectralEmbedding등의 방법이 있다.
(2) 하이퍼 파라미터의 최적화
기계학습을 실행할 때, 학습 방법 등을 조정하는 수치를 하이퍼 파라미터라고 한다.
그리드 서치, 크로스밸리테이션 등의 방법이 있다.
4. scikit-learn의 사용 방법
scikit-learn은 다양한 알고리즘이 포함되어 있는 라이브러리이기 때문에, 필요한 알고리즘을 호출하여 사용한다.
여기서는 간단한 코드를 사용해서 개요에 대해 알아본다.
scikit-learn을 사용한 프로그램은 기본적으로 아래의 구성이다.
1) 라이브러리 임포트
2) 학습 데이터나 테스트 데이터 준비
3) 알고리즘 지정과 학습 실행
4) 테스트 데이터로 테스트
5) 필요에 따라 정밀도 등을 시각화

5. scikit-learn을 사용한 기계학습(1)
그럼 scikit-learn을 사용한 기계학습에 도전해보자.
이번에는 scikit-learn의 토이 데이터 세트에 있는 '수기 숫자 데이터 세트'를 사용한다.
아래는 아나콘다를 사용한 예이다.
1) 데이터 세트 읽어 들이기
처음에는 데이터 세트를 읽어 들여 어떤 데이터가 저장되어 있는지 확인해본다.
아래의 코드를 입력하면 실행된다.
# scikit-learn ライブラリの読み込み
from sklearn import datasets
# 手書き文字セットを読み込む
digits = datasets.load_digits()
# どのようなデータか、確認してみる
import matplotlib.pyplot as plt
plt.matshow(digits.images[0], cmap="Greys")
plt.show()
2) 훈련 데이터와 테스트 데이터 준비
데이터 세트에는 '수기 숫자의 이미지 데이터'와 그것에 대한 '숫자'가 포함되어 있다.
데이터를 훈련 데이터와 테스트 데이터로 나눠, 훈련 데이터를 학습한 결과를 테스트 데이터로 검증하자.
# 画像データを配列にしたもの(numpy.ndarray型)
X = digits.data
# 画像データに対する数字(numpy.ndarray型)。ラベルと言う
y = digits.target
# 訓練データとテストデータに分ける
# 訓練データ :偶数行
X_train, y_train = X[0::2], y[0::2]
# テストデータ:奇数行
X_test, y_test = X[1::2], y[1::2]
3) 학습
그럼, 모델로 학습을 실시해보자. 아래는 SVM이라고하는 알고리즘을 선택했다.
# 学習器の作成。SVMというアルゴリズムを選択
from sklearn import svm
clf = svm.SVC(gamma=0.001)
# 訓練データとラベルで学習
clf.fit(X_train, y_train)
4) 모델의 평가
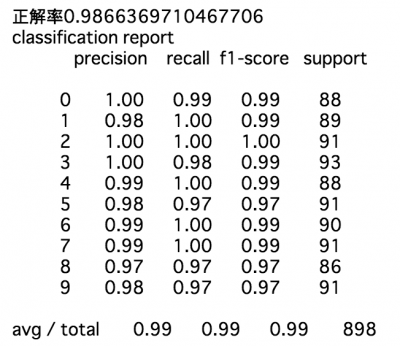
최종적을 모델의 학습 결과를 테스트 데이터를 이용해서 평가해보자.
# テストデータで試した正解率を返す
accuracy = clf.score(X_test, y_test)
print(f"正解率{accuracy}")
# 学習済モデルを使ってテストデータを分類した結果を返す
predicted = clf.predict(X_test)
# 詳しいレポート
# precision(適合率): 選択した正解/選択した集合
# recall(再現率) : 選択した正解/全体の正解
# F-score(F値) : 適合率と再現率はトレードオフの関係にあるため
print("classification report")
print(metrics.classification_report(y_test, predicted))실행결과는 아래와 같다. 간단하게 기계학습을 시도해 볼 수 있었다.
6. scikit-learn을 사용한 기계학습(2)
다음은 기계학습 알고리즘을 로지스틱 회귀로 변환해보자. 학습기의 작성의 2행을 아래와 같이 변경한다.
# 学習器の作成。ロジスティック回帰というアルゴリズムを選択
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()다른 코드는 변경할 필요는 없다. 이렇듯, scikit-learn으로는 모델을 간단히 변경하여 머신 러닝을 실시 할 수 있다.
이것에 대한 모델 평가도 실시해보자. 실행 결과는 아래와 같다.

7. scikit-learn에 대해 더 자세하게 배우고 싶다면
공식 사이트에서 제공되는 연습 문제를 풀어보면서 더 자세히 배울 수 있다.
https://scikit-learn.org/stable/tutorial/basic/tutorial.html
An introduction to machine learning with scikit-learn — scikit-learn 0.22.2 documentation
scikit-learn.org
참고자료
https://techacademy.jp/magazine/17375#sec1
https://ai-kenkyujo.com/2020/02/28/scikit-learn/
'IT > 언어' 카테고리의 다른 글
| [python] ArgumentParser(argpaser)의 사용법 간단 정리 (0) | 2020.05.20 |
|---|---|
| [python] 리스트의 요소 추가와 다른 리스트와의 결합 (0) | 2020.05.19 |
| [python] Iterator와 Generator (4) | 2020.05.13 |
| [python] Pandas란 (0) | 2020.04.20 |
| [python] Scikit-image 라이브러리란 (0) | 2020.04.20 |